
BlaBlaCar is one of the world’s leading community-based travel networks. With operations in 21 countries, they connect millions of drivers and passengers every month through long-distance carpooling, intercity buses, and short-distance ridesharing, all through a single, integrated mobility platform.
Behind that scale is a lean, forward-thinking engineering team, one that has a track record of adopting advanced practices years before they become industry standard. Over the past decade, BlaBlaCar has quietly built one of the most mature reliability stacks in the industry. They migrated to containers in 2018, implemented full-stack observability by 2020, and rolled out feature-level SLOs by 2024 to connect system health directly to user experience.

Now, they’re exploring what comes next: whether AI can assist with incident response not by following static rules, but by learning to reason through real production signals like an experienced SRE. This isn’t about patching a broken system. BlaBlaCar’s infrastructure works well. But even strong systems have limits, especially when knowledge is distributed and the environment is large. The goal is to reduce manual correlation, surface insights faster, and give every team a consistent first line of investigation, without introducing additional complexity.
It’s a practical step toward a broader question: can AI not just react, but reason? And if so, what does that unlock for engineering teams that are already operating at a high level?

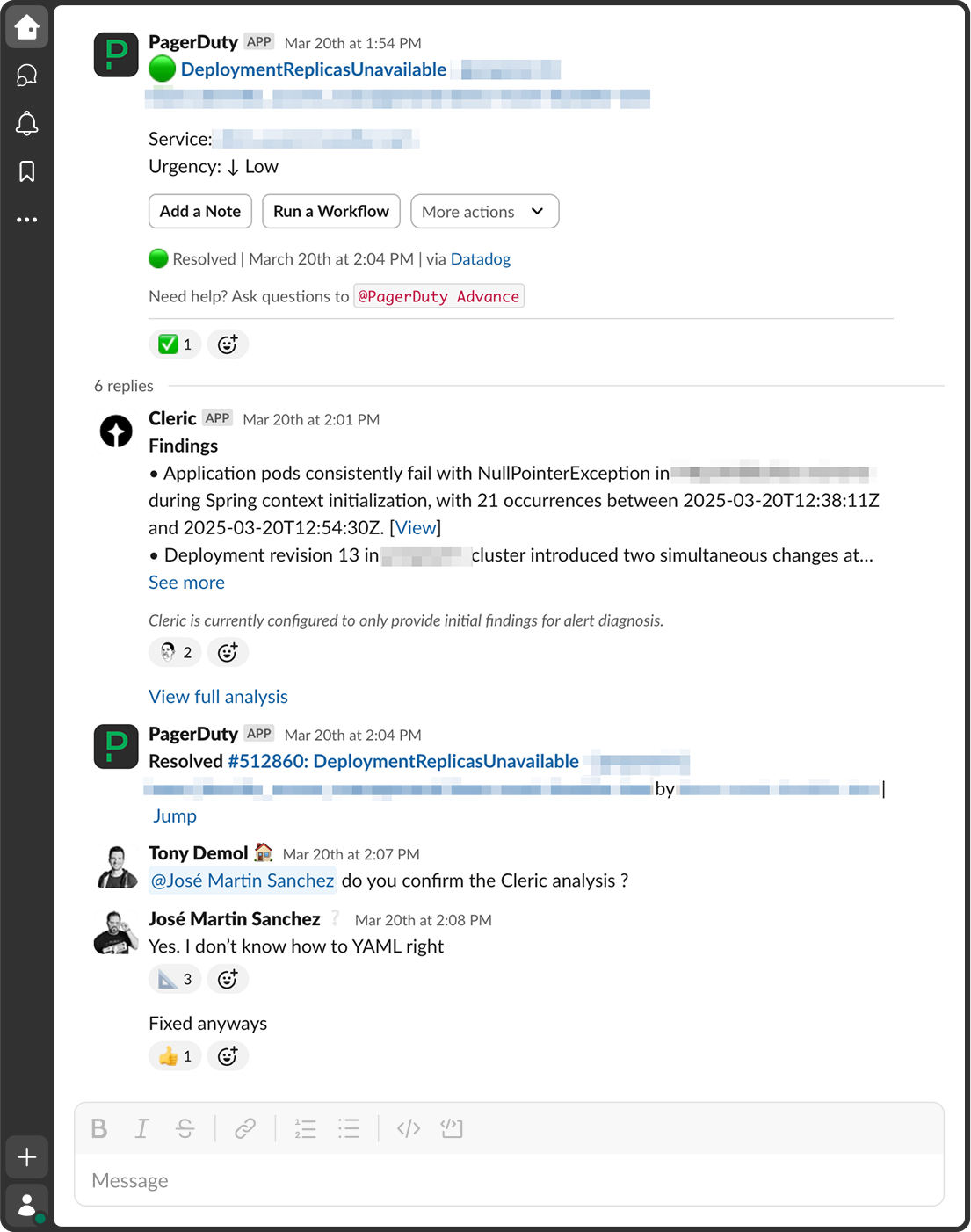
That’s where the partnership with Cleric comes in. BlaBlaCar introduced Cleric into their Slack alerting channels to test whether an AI system could investigate real alerts in real time. Not just label them, but reason through them. Within weeks, Cleric was identifying pod crashes, correlating deployment failures, and surfacing dependency issues that would otherwise take several engineers and multiple back-and-forths to isolate.
During the three-team pilot, Cleric worked every alert type but proved strongest on Kubernetes Mixin alerts. Rolling Cleric out to all 20-plus teams would let it take on about 10 percent of BlaBlaCar’s total monthly alerts (roughly 1,400). It responds directly in Slack with structured summaries, log analysis, and root cause candidates. Teams score its investigations and provide feedback, and in several alert categories, it’s already delivering findings on par with human responders. One team reported that 78 percent of Cleric’s investigations on core infrastructure issues contained at least one actionable finding.
The partnership between BlaBlaCar and Cleric goes beyond proving capabilities. Fundamentally, it’s about learning from one of the most advanced engineering teams how an AI SRE should think, operate, and deliver value. What makes this effort notable isn’t just the accuracy, it’s the intent. BlaBlaCar is aiming to give every team a first responder with reasoning patterns of a senior engineer that never gets tired.
BlaBlaCar’s approach validates what we’re seeing among engineering organizations that think beyond today’s constraints. They’re not just solving current problems, they’re exploring how AI can fundamentally change incident response in complex, distributed environments.
“Our goal isn’t complete alert coverage,” says Maxime. “It’s intelligent coverage. Using Cleric’s insights to proactively address and eliminate systemic issues.”
Read How They’re Shaping the Future
Curious how teams are actually putting AI to work in operations? This case study walks through BlaBlaCar’s experimental approach, gradual rollout, and lessons from eight months of pushing the boundaries of what’s possible with AI in production environments.
Read the complete BlaBlaCar case study here.