

BlaBlaCar may have cemented its status as France’s first unicorn in 2015, but its enduring success as a tech giant stems from an engineering culture that consistently embraces technological experimentation and innovation to stay ahead of the curve. Operating in 21 countries, BlaBlaCar is a household name in Europe, Latam, and India, and a true multimodal mobility platform. Its services include long-distance carpooling that links drivers with empty seats to passengers on the same route, its own intercity bus service (BlaBlaCar Bus), a bus-and-train ticket marketplace, and short-distance ridesharing, together forming a single, integrated transportation network.
BlaBlaCar’s reliability backbone is a lean, five-person SRE team embedded within a 40-person “Foundations” group. Together, they empower over 200 engineers in:
- Running a fully containerized service architecture on Kubernetes with an Istio-based service mesh
- Supporting more than 200 CI/CD deployments every day
- Providing unified observability across all services
- Enforcing SLO-driven monitoring adopted by 40+ engineering teams
This tight, focused setup keeps the platform robust and scalable.
For BlaBlaCar, infrastructure reliability and availability aren’t just technical concerns but business imperatives: any downtime directly impacts users’ ability to find rides and coordinate travel. Alerts serve as an early warning system for technical issues that could prevent drivers and passengers from connecting. Even brief outages can affect revenue and erode user trust. With operations spanning geographies and time zones, resilient infrastructure forms the invisible foundation behind millions of successful journey matches every day.
Even with a strong “you build it, you run it” culture enabled by a standardized observability stack and feature-level SLOs, mean time to recovery for high-urgency incidents is currently approaching 2 hours. Even with monthly trend reviews, it’s often difficult to correlate root causes across teams. “We see that even if we do monthly reviews with every team, sometimes it can be pretty hard to identify a clear action item we want to take to reverse a negative trend on alert fatigue. It’s quite a lot of work and analysis to get to the insight that is impactful,” says Damien Bertau, Engineering Manager, SRE Team.
Rather than view this complexity as a blocker, BlaBlaCar sees an opportunity to evolve how teams respond. Damien explains, “What we struggle with most is finding the root cause, because our alerting is primarily based on symptoms. With so many interconnected services, multiple teams often detect issues simultaneously saying ‘I have a problem,’ ‘me too,’ but identifying where it originates costs us valuable time.” Maxime Fouilleul, Head of Foundations, adds: “We observe that scoping an issue when it occurs is really challenging. An SLO might be triggering alerts for one service, but the real problem could be in a dependency. Isolating the actual source takes time because we can’t immediately see which services are affected by a particular issue. The real challenge is effectively scoping the problem.”

Further, knowledge is unevenly distributed across the organization. “The maturity on Kubernetes is really different according to service teams,” notes Maxime. “Across our software engineering teams, Kubernetes maturity varies. Some teams are deeply experienced, while others are still building confidence with the fundamentals. That’s also why we’re exploring whether AI can help establish a consistent baseline for level one incident management, and, over time, surface learnings to support teams as they continue to ramp up and grow.”
BlaBlaCar’s engineering leadership recognizes the emerging potential of AI not as a way to replace existing systems but to enhance a well-functioning setup and unlock new efficiencies. They aren’t simply trying to reduce toil. They see a moment to rethink how incident response works in an AI-augmented future:
- Recovery speed: Can we slash recovery time by automating repetitive investigations?
- Cross-service intelligence: Can we create a system that automatically connects signals across our architecture to surface root causes faster?
- Expertise multiplication: Can we extend the diagnostic reach of our most experienced engineers to every team?
Why BlaBlaCar Chose Cleric to Pursue a Shared Vision for Intelligent Systems
Embracing BlaBlaCar’s “Be Lean, Go Far” ethos, engineering leadership adopts agentic AI to scale their impact while maintaining a lean and agile foundation. “I see Cleric functioning as an SRE companion available for our Software Engineers. An SRE in my team should maintain a global view across all engineering teams. This means if one team has already solved an alert, we can apply that knowledge elsewhere. It’s really about leveraging SRE expertise across different areas of responsibility,” explains Maxime. “By investing in smart tooling and integrating AI-driven SRE capabilities, we’re hoping to empower our SREs to concentrate on strategic, high-impact initiatives.”
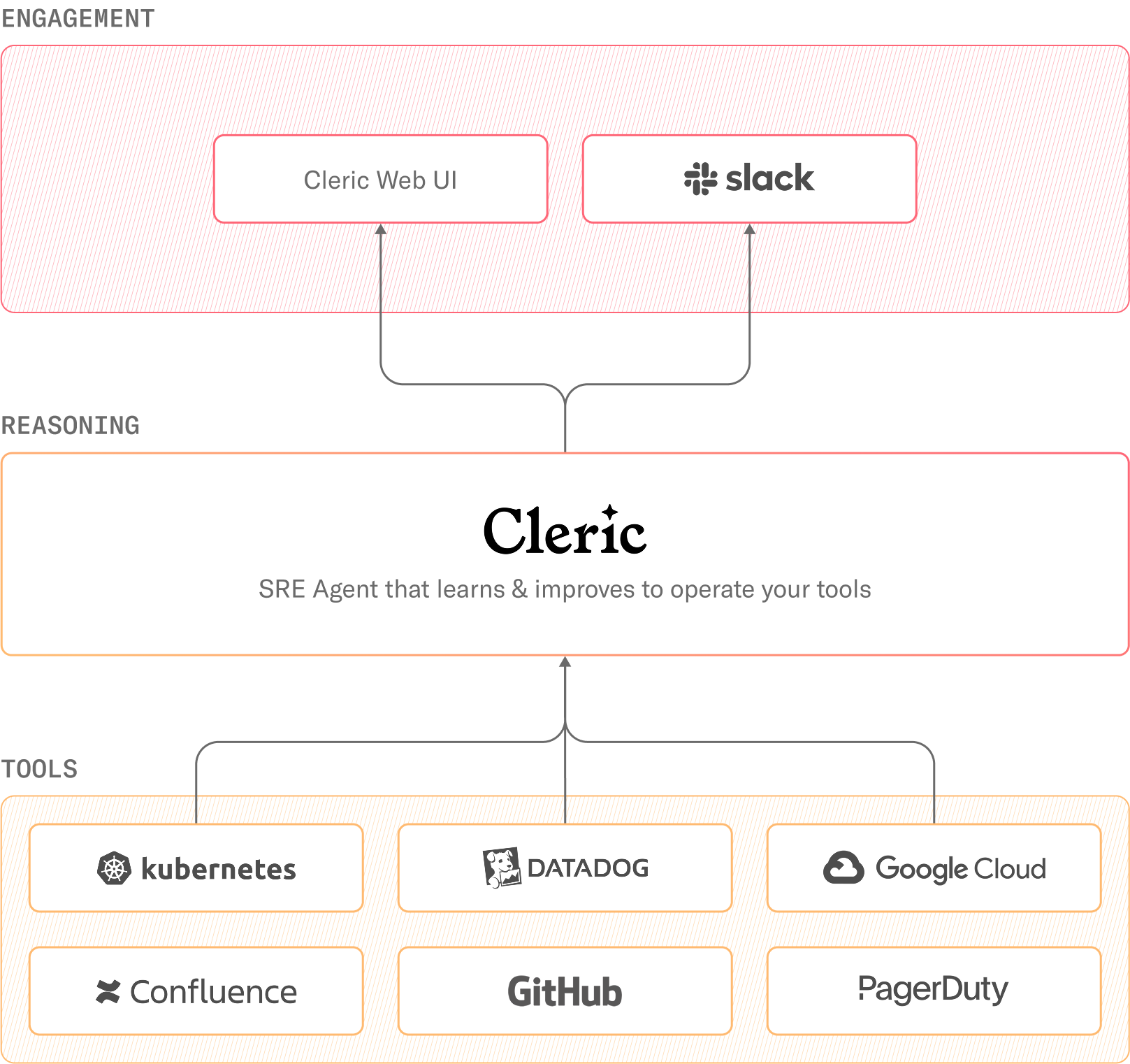
To support that vision, Cleric integrates seamlessly with the BlaBlaCar stack: Kubernetes, Datadog, PagerDuty, and Confluence. Once introduced into a Slack alerting channel, Cleric begins autonomously investigating and responding to select alerts, offering actionable insights in the same place engineers already work. “We want everything centralized in Slack because that’s where we interact daily,” Damien says. “Cleric integrates directly into Slack, making troubleshooting faster without forcing engineers to switch between tools.”
Built to investigate like a human, not just follow rules, Cleric aligns naturally with BlaBlaCar’s forward-thinking engineering culture. Both companies recognize the opportunity AI presents: a chance to reduce the burden of manual investigation for teams that need it, and to explore how AI can further optimize operations in environments that are already mature. For BlaBlaCar, it’s a way to push the boundaries of what’s possible with incident response. For Cleric, the partnership is about more than proving capabilities, it’s about learning from one of the most advanced engineering teams how an AI SRE should think, operate, and deliver value within large-scale, distributed systems. Together, they’re exploring a new frontier: teaching AI to reason through alerts the way a seasoned SRE would.
Early Deployment and Expansion
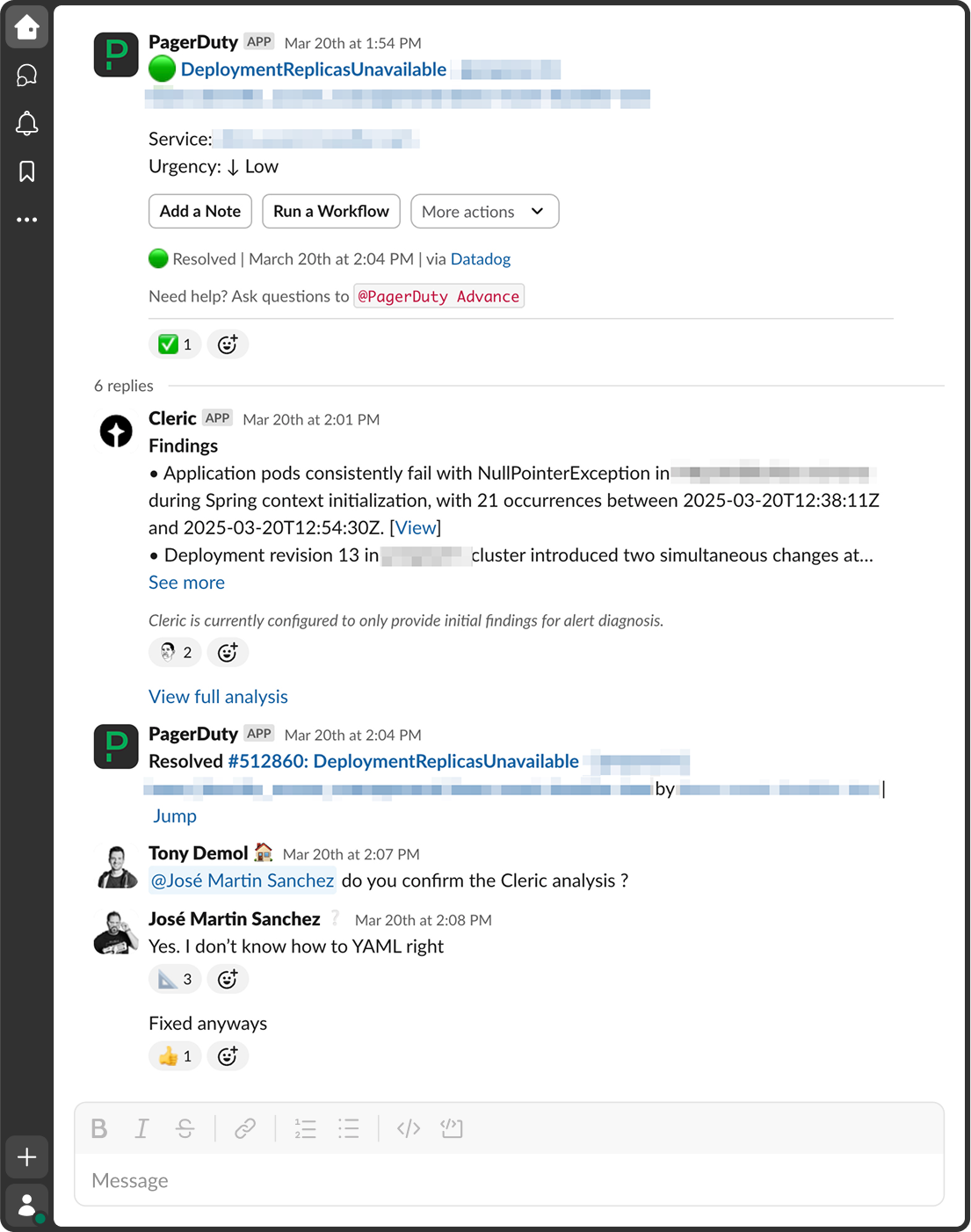
In August 2024, Cleric was introduced in the SRE helpdesk and alerting channels and configured to handle alerts from BlaBlaCar’s Chaos app, an internal demo application designed to simulate production failure scenarios in Kubernetes. After demonstrating value in those controlled experiments, Cleric’s role expanded. In late October, BlaBlaCar added Cleric to the Database Reliability team’s alerting channels, where it began acting as level one incident response. In this context, Cleric learned to interpret time series data and logs in the same way the DBRE engineers would.
By late January 2025, the Identity and Access Management (IAM) team, a Platform team dealing with high alert volumes, added Cleric to their Slack alerting channel. A senior engineer sampled and scored its investigations, rating their accuracy from 1 to 5. Within three weeks, without any prior guidance on the domain, Cleric earned its first perfect score for correctly diagnosing an “Upstream Retry Limit Exceeded” alert. By March, two more teams had adopted Cleric. Today, it responds to a range of Kubernetes Mixin alerts representing about 10% of BlaBlaCar’s total alert volume, approximately 1,400 alerts per month.
In Q1 2025, BlaBlaCar began quantifying Cleric’s impact. A key milestone was time to first value, the point at which Cleric’s investigations consistently matched on-call engineer quality for a given alert category. Cleric reached this milestone in six weeks with the Identity and Access Management (IAM) team, and in just three weeks with the Engage team. Between February 12 and April 10, Cleric conducted 553 investigations for the IAM team, receiving 48 feedback reports from engineers. Cleric proved especially effective on deployment failures, pod crashes, application scaling issues, and job failures. Engineers reported at least one actionable insight in 78% of these investigations. However, performance was weaker on higher-order incidents like SLO burn-rate breaches and anomaly detection, where only 50% of investigations yielded useful findings.
For Adrien Hellec, senior backend engineer on the IAM team, Cleric’s value lies in surfacing the obvious instantly. “These are simple alerts, it’s always the same: you have to check the logs, and there you find the problem immediately. Cleric can help a lot here.” While Damien highlights broader value:
For senior engineers, Cleric saves valuable minutes per alert. But for junior engineers or those less familiar with our infrastructure, Cleric can significantly shorten investigation times by immediately reducing the search space and surfacing the relevant data sources.

Cleric in Action
Cleric has repeatedly proven its ability to diagnose and summarize incidents with speed and precision. When an IAM service experienced pod restart loops, Cleric retrieved the container logs, identified a dependency injection failure, and found the root cause directly in the error message. It presented results within minutes. “Pod crash looping alerts are a common issue, and Cleric has been effective at handling them,” Adrien noted. “They’re often caused by a faulty deployment that prevents the application from starting properly.”
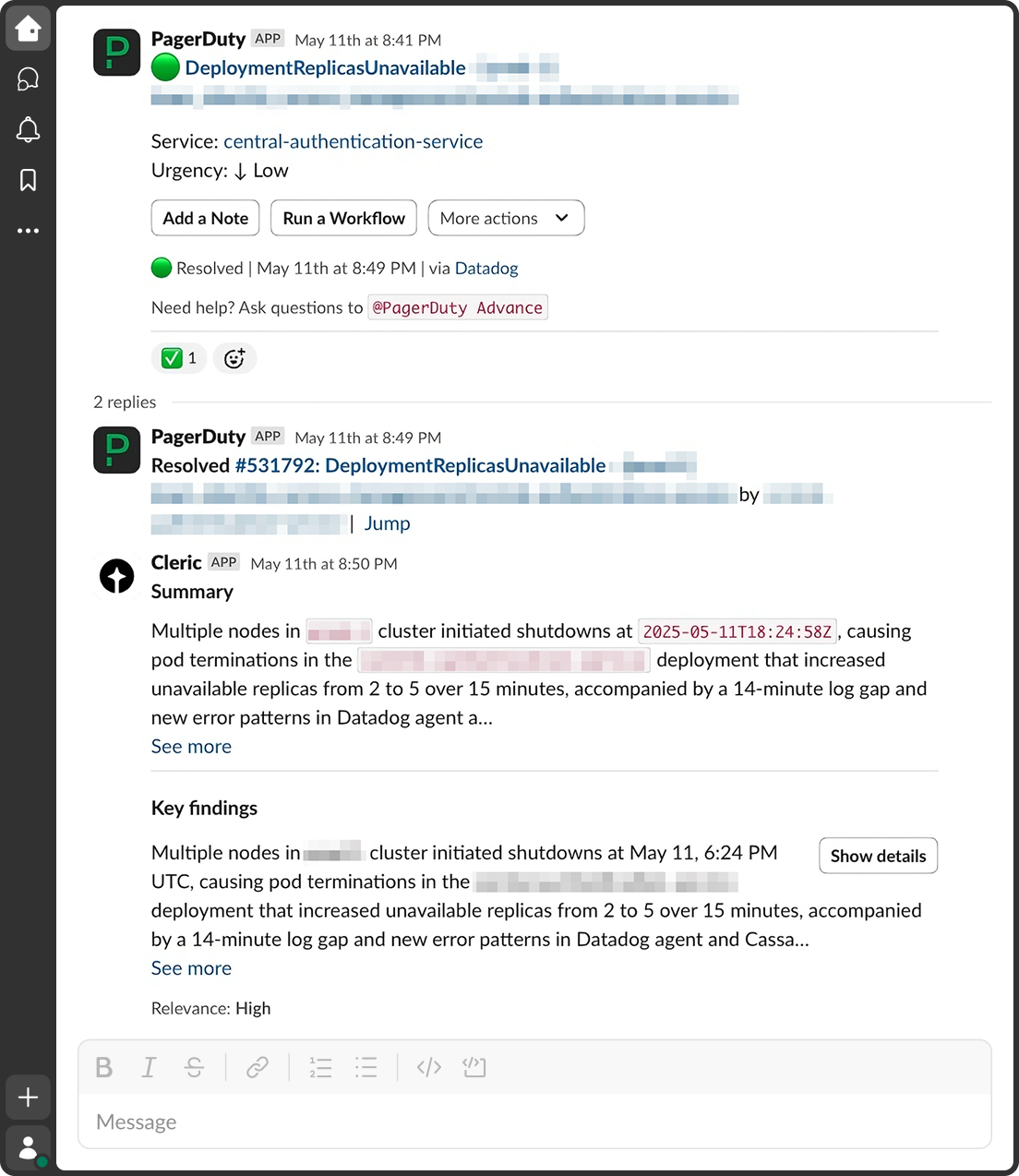
In another case, Cleric helped identify when one service was impacting another. It detected an error spike, found upstream error logs, correlated the issue to a recent deployment, and highlighted the cross-service link. Most recently, Cleric responded to a cluster-wide instability. It detected simultaneous node shutdowns as they began, quantified the rise in unavailable replicas for a critical auth service (from 2 to 5 in just 15 minutes), flagged a 14-minute telemetry gap, and surfaced new error patterns in monitoring and database connectivity. It delivered a concise summary in the incident channel within minutes, pointing engineers straight to the underlying infrastructure event. “The analysis was spot-on,” said Tony Demol, Staff Software Engineer in IAM team. “Cleric cut through the noise and told us exactly why pods were disappearing and where to look next.”
These types of cross-team investigations often demand significant coordination. “Even by myself, I’m not able to tell which service is calling any other service if I’m looking at other teams,” Adrien noted. For both BlaBlaCar and Cleric, moments like these highlight the deeper potential of AI, not just as a helpful assistant, but as a path to rethinking how incident response works in complex, distributed environments.
Together, they’re exploring how an AI teammate could accelerate diagnosis, surface inter-service relationships, and offer engineers clearer starting points. AI offers the chance not to hand over control, but to give engineers better visibility, faster paths to root cause, and a shared foundation for understanding issues that span teams.
What’s Next
Cleric’s early performance has validated a good potential for broader adoption. By focusing first on tractable alert volumes (10-15%), BlaBlaCar proves value while scaling responsibly. “Our goal isn’t complete alert coverage,” says Maxime. “It’s intelligent coverage. Using Cleric’s insights to proactively address and eliminate systemic issues.”
We see Cleric’s potential to significantly reduce our operational load. We are particularly eager to see it handle complex scenarios like SLO burn rate alerts, which are often less intuitive and directly impact user experience. Saving time in these critical areas would be a game-changer.
Together, BlaBlaCar and Cleric are now focusing on improving Cleric’s ability to work across team boundaries:
- Monitoring deployment and release channels to correlate alerts with recent changes
- Helping teams recognize when alerts might be caused by issues in other services
- Automatically identifying when alerts might be caused by common platform services
- Significantly reducing manual effort in preparing SLO and alerting reviews, saving time for both SREs and service teams
Cleric’s footprint expands alongside BlaBlaCar’s global operations, focusing on teams experiencing alert fatigue. As BlaBlaCar’s business scales globally, Cleric adapts by learning from resolved incidents and handling increasingly complex cross-service dependencies. This ensures that their “you build it, you run it” culture remains sustainable, despite the growing complexity of their distributed architecture.
As BlaBlaCar’s systems grow more complex, the goal is to help engineers respond faster, with clearer context and less overhead. Every alert Cleric handles adds to its understanding of how real teams investigate real incidents. The long-term aim is safe, automatic remediation: recommending or executing fixes based on patterns it has seen work before, just as a seasoned SRE would, drawing on experience to act quickly and with confidence.
BlaBlaCar doesn’t need to fix broken processes. What they’re doing works. The opportunity is to push it further, to see how far AI can go when it learns from people operating at the highest level. It’s about making responses faster, more consistent, and easier to scale, without compromising how teams work today.
We are actively measuring Cleric’s performance across teams at BlaBlaCar, and plan to follow up with part 2, where we’ll report on Cleric’s broader adoption and impact on key results.