Key Functions
What Cleric does
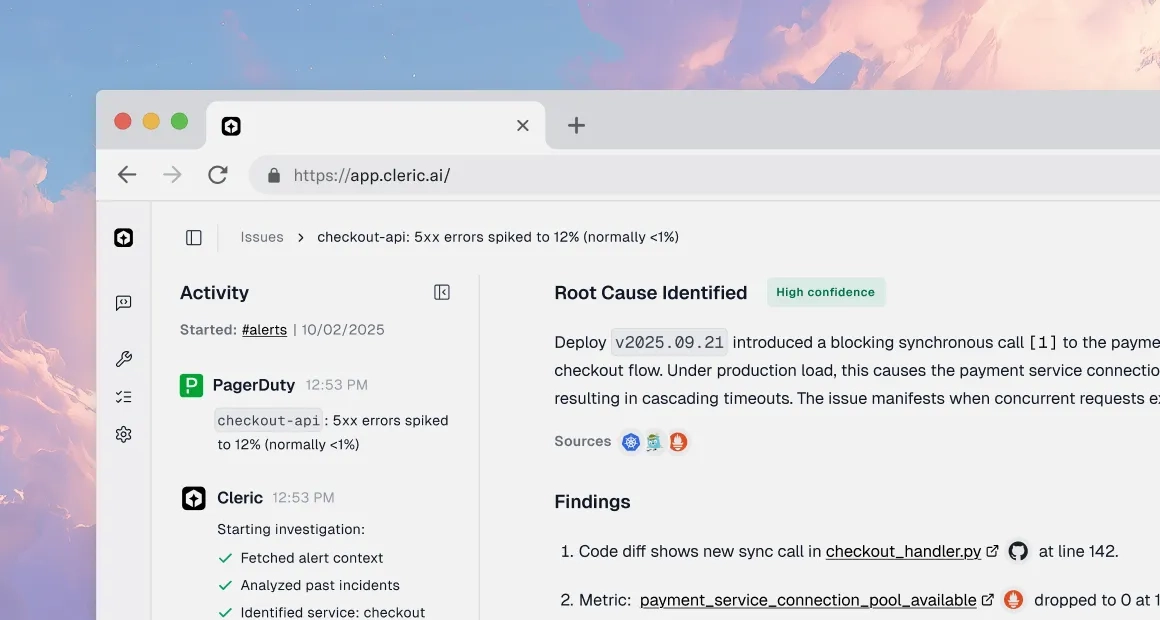
Instant Analysis
Starts investigating the moment an alert fires in your microservices architecture, pulling from observability tools.
Hypothesis-Driven
Tests possible causes across services, queues, and databases, like tracing a failure from an API gateway to a downstream database.
Clear Deliverable
Delivers a concise diagnosis with evidence and specific fix recommendations (e.g., adjust queue settings) to Slack, tagged to the right owner.
Key Advantages
How Cleric stands out
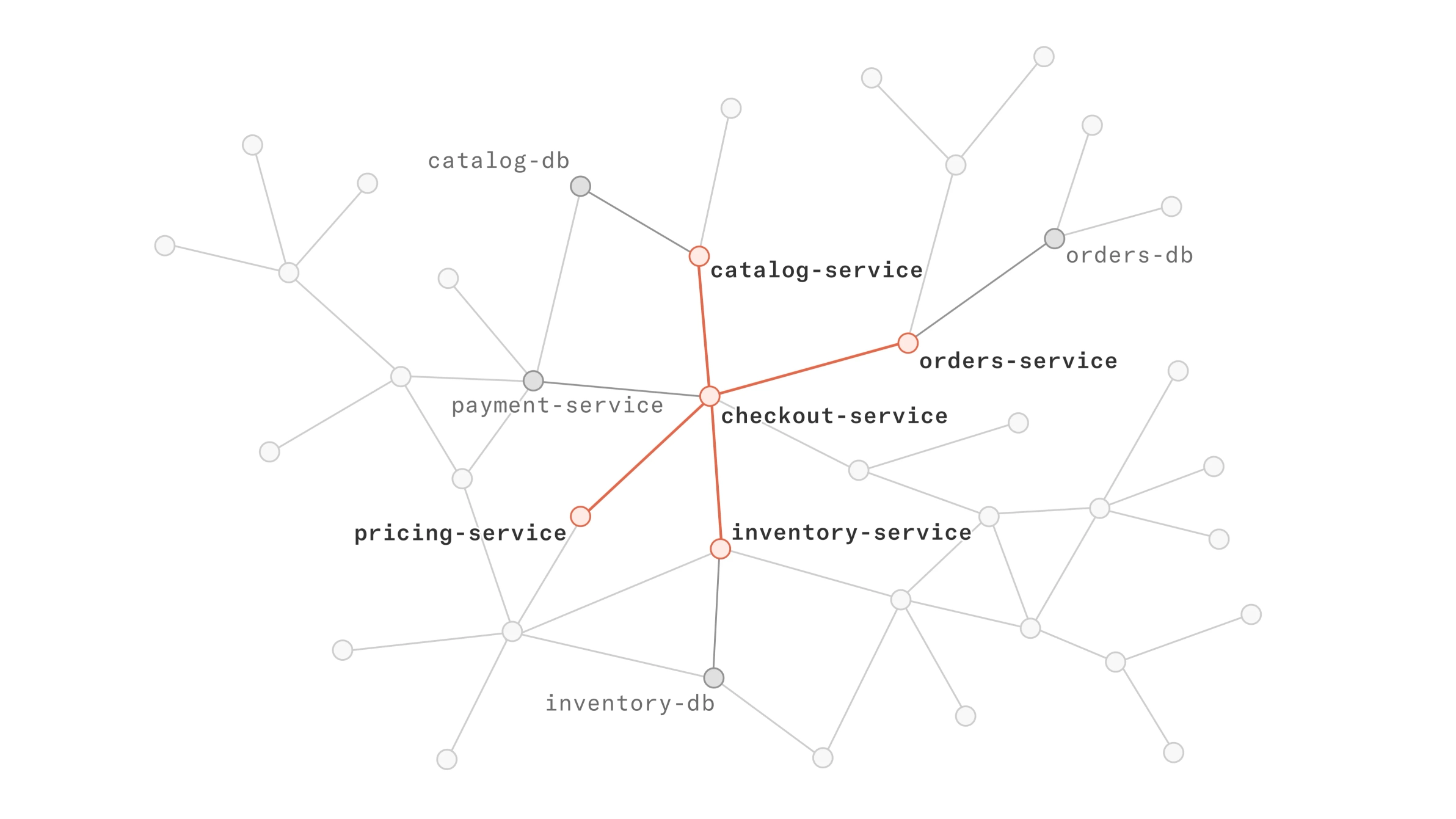
End-to-End View
Tracks failures across microservices architectures without manual correlation.
Blast Radius Mapping
Identifies all impacted services to scope the issue quickly.
Evidence-First
Provides diagnoses backed by real telemetry, filtering false positives with confidence-scored results.