Key Functions
What Cleric does
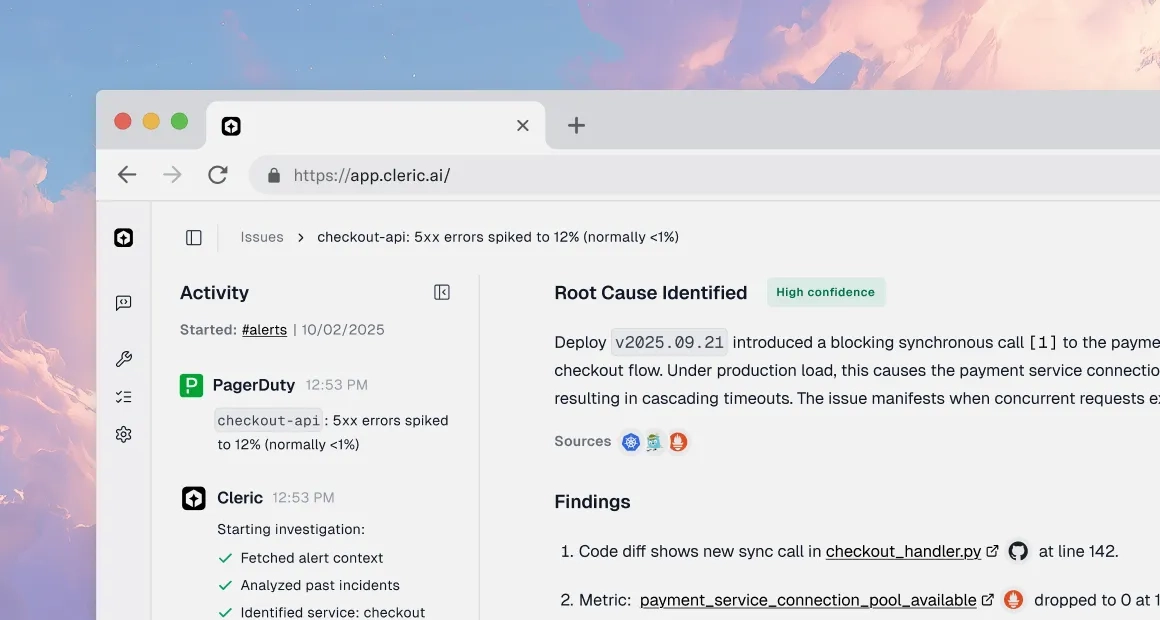
Instant Analysis
Starts investigating the moment a deployment-related alert fires from your CI/CD pipeline or observability tools.
Hypothesis-Driven
Tests possible causes across code, config, and infrastructure, linking issues like error spikes or latency to the specific deploy.
Clear Deliverable
Delivers a concise diagnosis with evidence and specific fix recommendations (e.g., revert a config change) to Slack, tagged to the right owner.
Key Advantages
How Cleric stands out
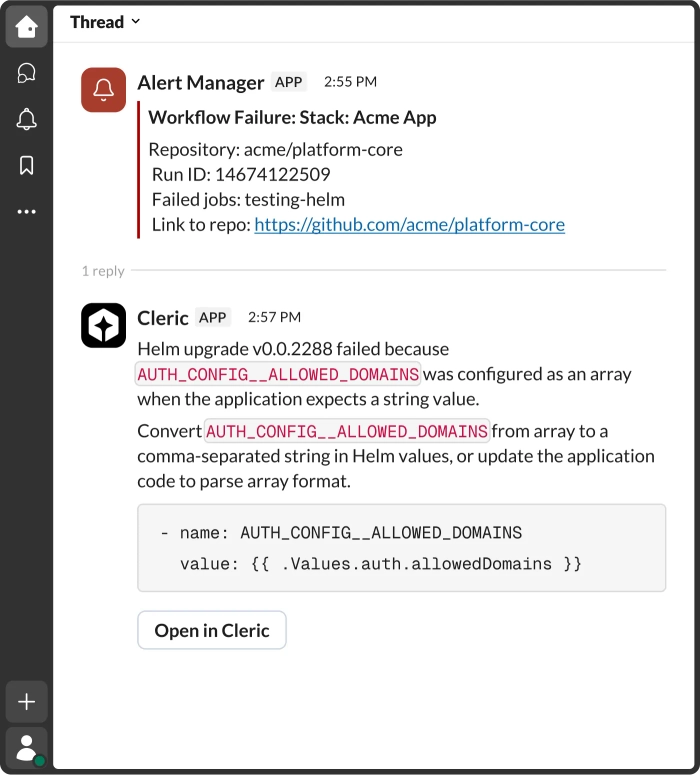
Root Cause to Deploy
Connects failures directly to the source change in your CI/CD pipeline.
Covers App + Infra
Handles issues from application regressions to infrastructure misconfigurations.
Deploy-Aware Reasoning
Understands what changed and when, ensuring fast and accurate diagnoses.