Key Functions
What Cleric does
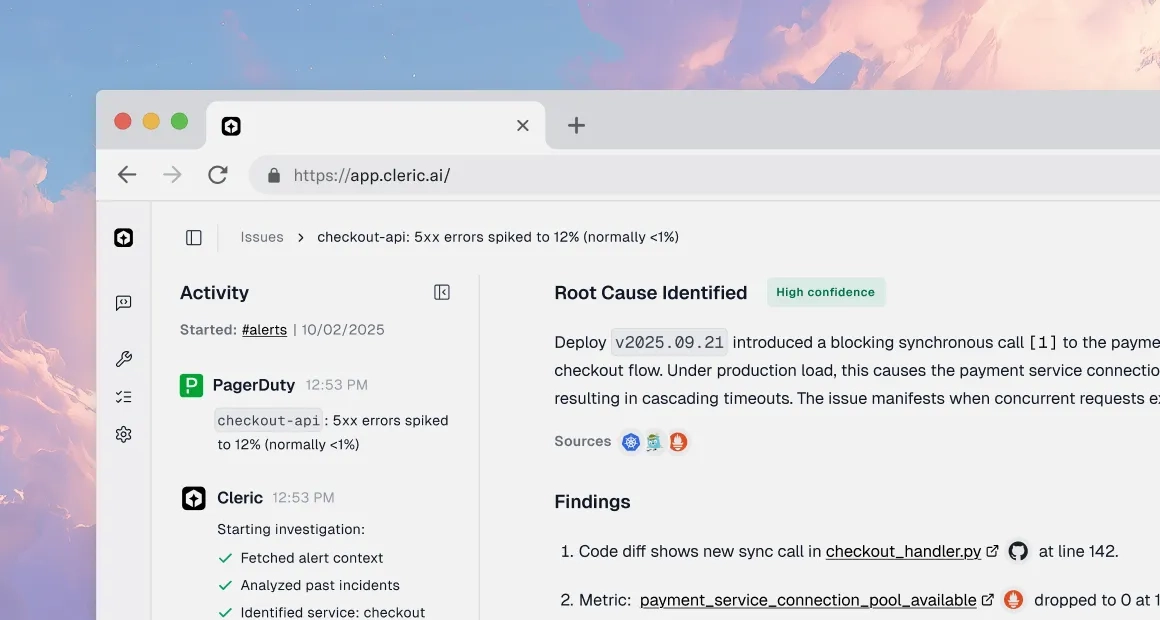
Instant Analysis
Kicks off the moment a Kubernetes alert fires from your observability tools or cluster.
Hypothesis-Driven
Builds a tree of possible causes, tests them against logs, metrics, and traces, and rules out noise.
Clear Deliverable
Sends a concise diagnosis with evidence and next steps to Slack, tagged to the right owner.
Key Advantages
How Cleric stands out
Full-Stack Kubernetes Coverage
Handles everything from workloads to control plane without extra setup.
Thinks Like an Engineer
Uses structured reasoning to test hypotheses, not brittle rules, for accurate results.
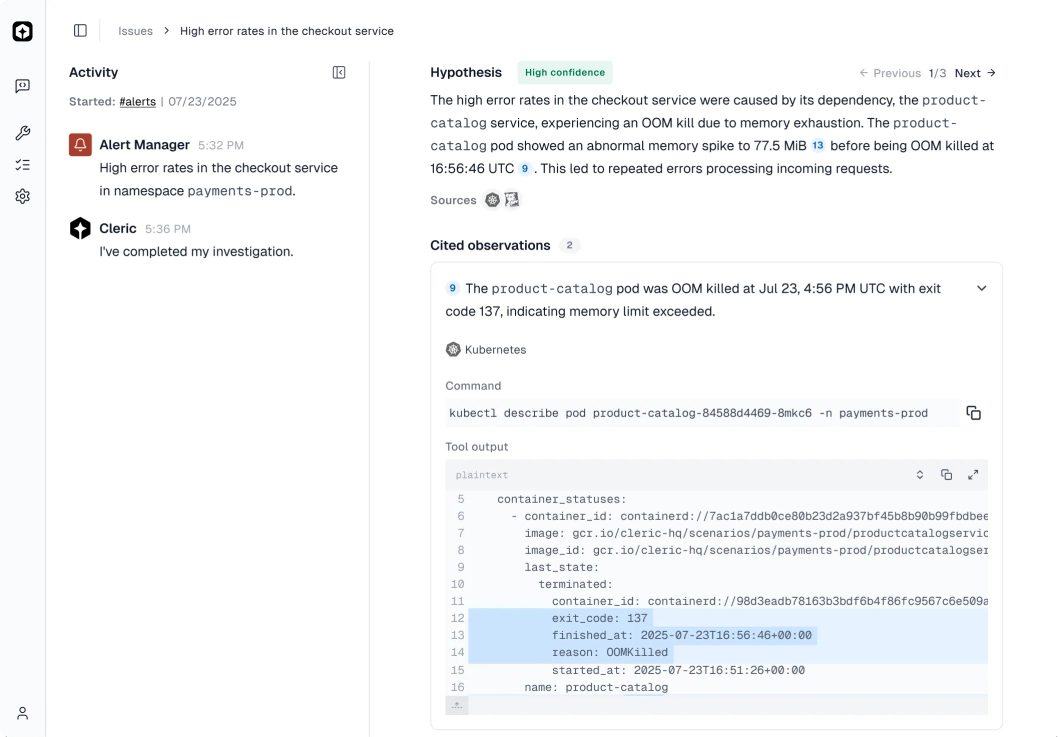
Transparent Results
Every diagnosis includes a confidence score and supporting data for quick validation.