Key Functions
What Cleric does
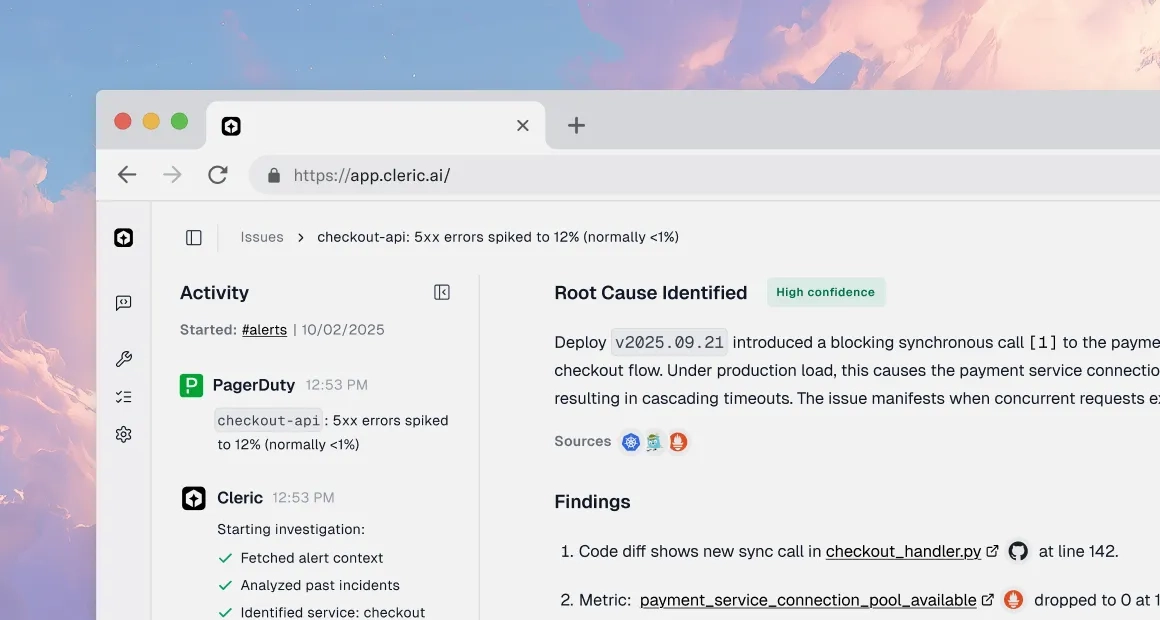
Instant Analysis
Starts investigating the moment a cloud infrastructure alert fires from your observability tools or cloud APIs.
Hypothesis-Driven
Tests possible causes across compute, networking, and managed services using telemetry and logs.
Clear Deliverable
Delivers a concise diagnosis with evidence and specific fix recommendations (e.g., adjust VPC routes) to Slack, tagged to the right owner.
Key Advantages
How Cleric stands out
Multi-Cloud Ready
Handles AWS, GCP, Azure, and hybrid stacks seamlessly.
Broad Coverage
Investigates issues from compute instances to managed services like databases and queues.
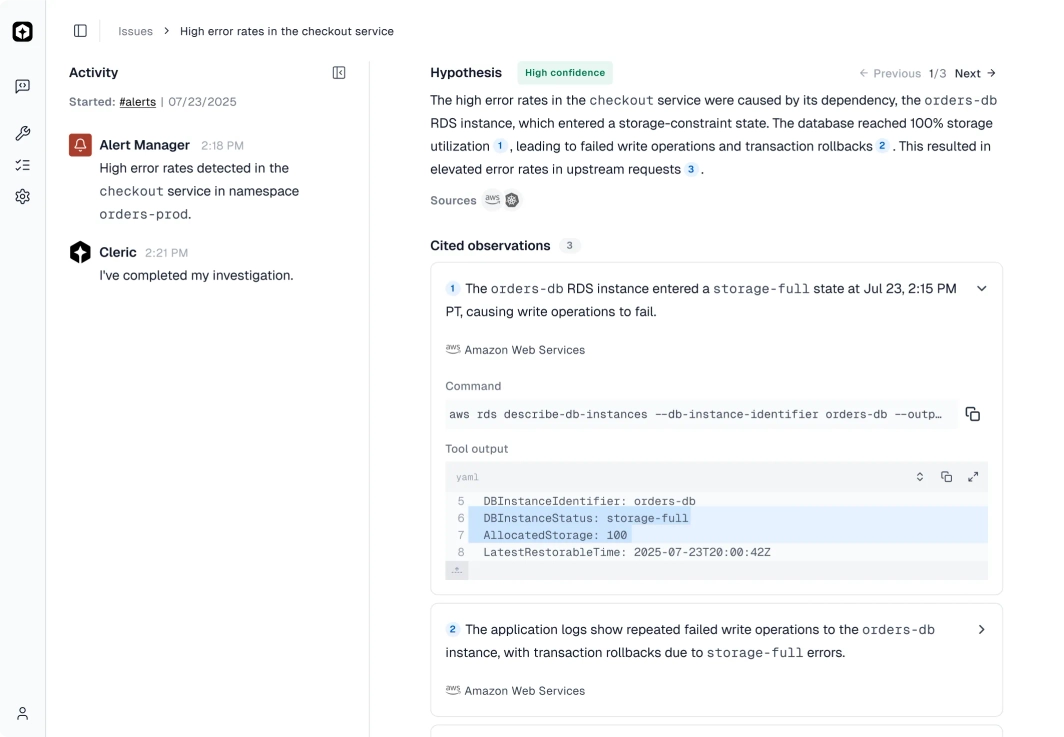
Evidence-Backed
Provides diagnoses with clear reasoning and confidence scores for quick validation.