
A note from our founders
In the last year, AI SRE has gone from being a string of letters that didn’t mean much to anyone (it would work great on a license plate though), to a term that is generating real interest.
There’s a growing awareness of the idea of using AI for software reliability. This maps to a recent report from Atlassian that found 63% of developers are currently using AI for incident response (with another 34% planning to).1
But this category is still so new that, when we have sales conversations or talk to our peers at conferences, we find that most people are just trying to get their heads around what the AI SRE landscape looks like.
We hear a lot of the same questions:
- Why wouldn’t we just build this ourselves?
- What about a platform that’s been around for 5 years, incident.io? When would we consider that vs. one of these new agentic startups?
- What about the Bits AI SRE for Datadog? Is it any good?
- We’re hearing about Traversal, Resolve, and Cleric; what are the differences between them?
We wrote this guide to help engineering leaders navigate these questions and more. Many guides stop short of naming any specific vendors, to remain more “evergreen” or avoid perceived bias. But we don’t think that’s what readers are really looking for. This space is changing quickly, and teams need concrete answers now.
We’ve named competitors directly because we think that’s more useful than a generic framework. Read their sections and ours with the same critical eye. We want teams to choose Cleric only if it’s truly the right fit, and they should do so with as much information as possible.
Shahram Anver & Willem Pienaar
Cleric Co-founders


Part 1: AI SRE — A New Kind of Production Intelligence
Summary
Production work already dominates most engineering bandwidth at high-scale companies. Only 16% of an engineer’s week goes to building, while 60% goes to wrangling production systems. Coding agents are making this dramatically worse by pushing the hard part of development to the right: validating AI-written code, understanding its effects in production, and debugging issues it introduces.
The work that eats the most time is cross-system investigation, where you reconstruct context across fragmented tools and test hypotheses. Modern agents are increasingly good at this type of reasoning. AI SRE is the category of agentic systems built to automate the detect → diagnose → remediate loop and capture the institutional knowledge that lives in Slack threads and senior engineers’ heads.
The biggest software engineering time suck: production operations
Over the past several years, LLMs have transformed software development. Adoption accelerated meaningfully in 2025. In a Stack Overflow Developer Survey, 84% of respondents say they use AI tools in their development process, and 51% report daily use.2 In a report from Atlassian, 99% of developers say they save time with AI coding tools and agents, with 68% saving more than 10 hours a week.
Agents have accelerated the development loop dramatically. Teams are shipping more code, more services, and more changes than ever before. But all of that code lands in the same place: production. And production hasn’t gotten any easier to operate.
What was already a dizzying graph of human-written services and their dependencies is now an explosion of AI-generated code interleaved with human code, multiplying the interactions and failure modes that need to be understood when something breaks. The development loop got faster. The production loop, the part where you figure out what went wrong and why, is still manual, high-latency, and increasingly overwhelmed.
A recent IDC analyst report broke down tasks by time spent, and found that only 16% of an average engineer’s time is spent doing application development; that’s about 6.5 hours in a 40-hour work week. But when you sum up the time spent on tasks like security, CI/CD, and monitoring, you get 60%, or 24 hours, spent wrangling production systems.3
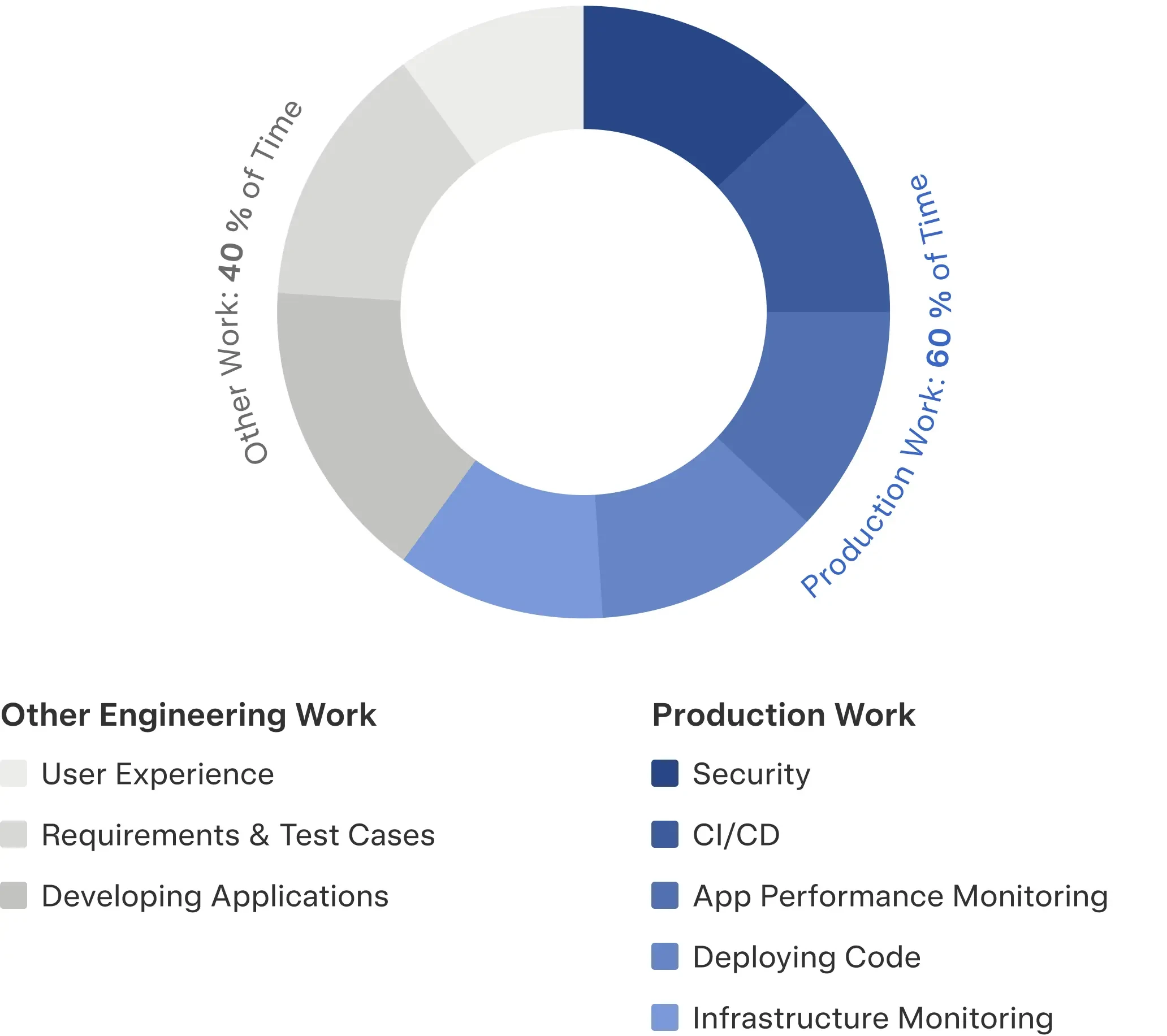
Engineering Time Allocation: Production Work Dominates
While AI accelerates coding, the majority of engineering effort remains in production operations.
What is driving production complexity?
Production work is becoming harder because:
- Distributed systems introduce non-obvious, cross-service failure modes
- Observability and infra tooling remain siloed
- Deployments happen continuously across multiple environments
- Agents increase code volume without eliminating validation work
The rise of distributed systems
Modern production environments look very different from those DevOps was originally designed to manage.
Enterprise Kubernetes adoption crossed 60% in 2024 and is projected to exceed 90% by 2027.4 Multi-cloud strategies are now standard. What used to be a handful of long-lived services has become dozens or hundreds of loosely coupled services communicating over APIs and event streams.
At the same time, documentation rarely keeps pace with architectural change. Teams change, services are rewritten, ownership shifts, and tribal knowledge accumulates informally in Slack threads and incident retros. New engineers inherit systems that have evolved organically over years.
The result is that debugging no longer means inspecting a single code path. It means reasoning about complex interactions between dependencies, and doing it under pressure, with incomplete information.
Explosion in tooling
To operate distributed systems, teams have accumulated a growing set of specialized tools:
- Okta’s Businesses at Work 2025 report found that the global average number of apps per organization surpassed 100 for the first time, reflecting continued year-over-year growth.5
- Grafana Labs’ 2024 Observability Survey found that 70% of teams use four or more observability technologies, with 68 distinct solutions cited across respondents.6
As a result, production work like debugging requires engineers to constantly context-switch and reconstruct state across an array of disconnected systems.
Agentic engineering
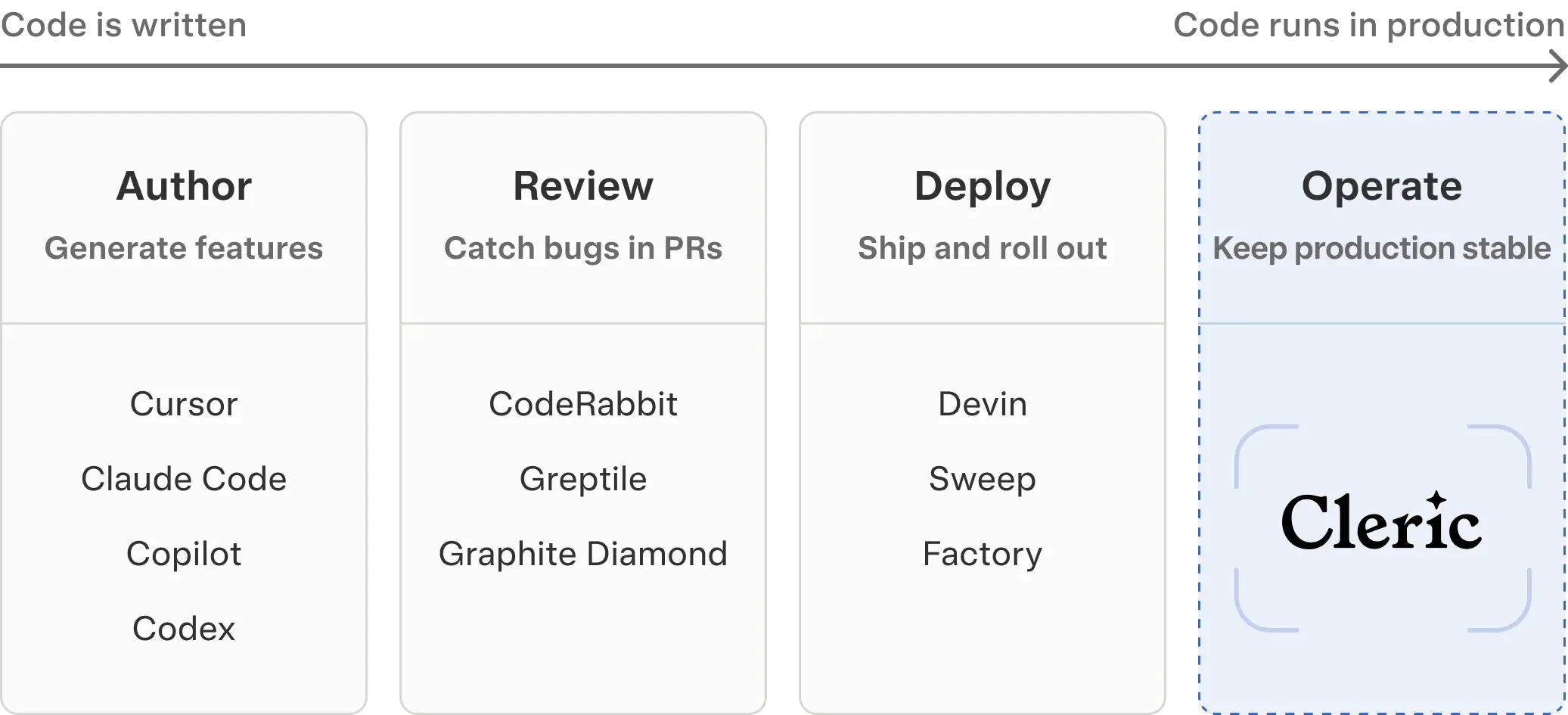
AI agents across the software lifecycle
Agents have colonized every stage — except after code lands in production. Code volume is rising sharply on the left. The work of understanding what it does in production is still done by humans.
Agents and AI coding tools have dramatically altered how much code enters production. When a single engineer can now 5x or even 10x their output, the volume of change starts increasing faster than a human team can realistically keep up with.
Meanwhile, work involving investigation, triage, change validation, and knowledge discovery is still largely constrained by human capacity. And that kind of work is only becoming more demanding, because of the rapid pace of change and the lower levels of trust in those changes.
Stack Overflow’s 2025 survey found that the most common frustration with AI-generated code is that it is “almost right, but not quite” (66%), and 45.2% of developers report that debugging AI-generated code is more time-consuming.7 In a separate report from DORA, only 24% of respondents said they trust AI-generated code “a lot” or “a great deal.”8
The breaking point
As a company becomes more successful and scales out, their production systems suck up more time, eventually dwarfing the aggregate time teams have to spend on application development. Engineering orgs find themselves facing a widening gap between operational load and available cognitive capacity.
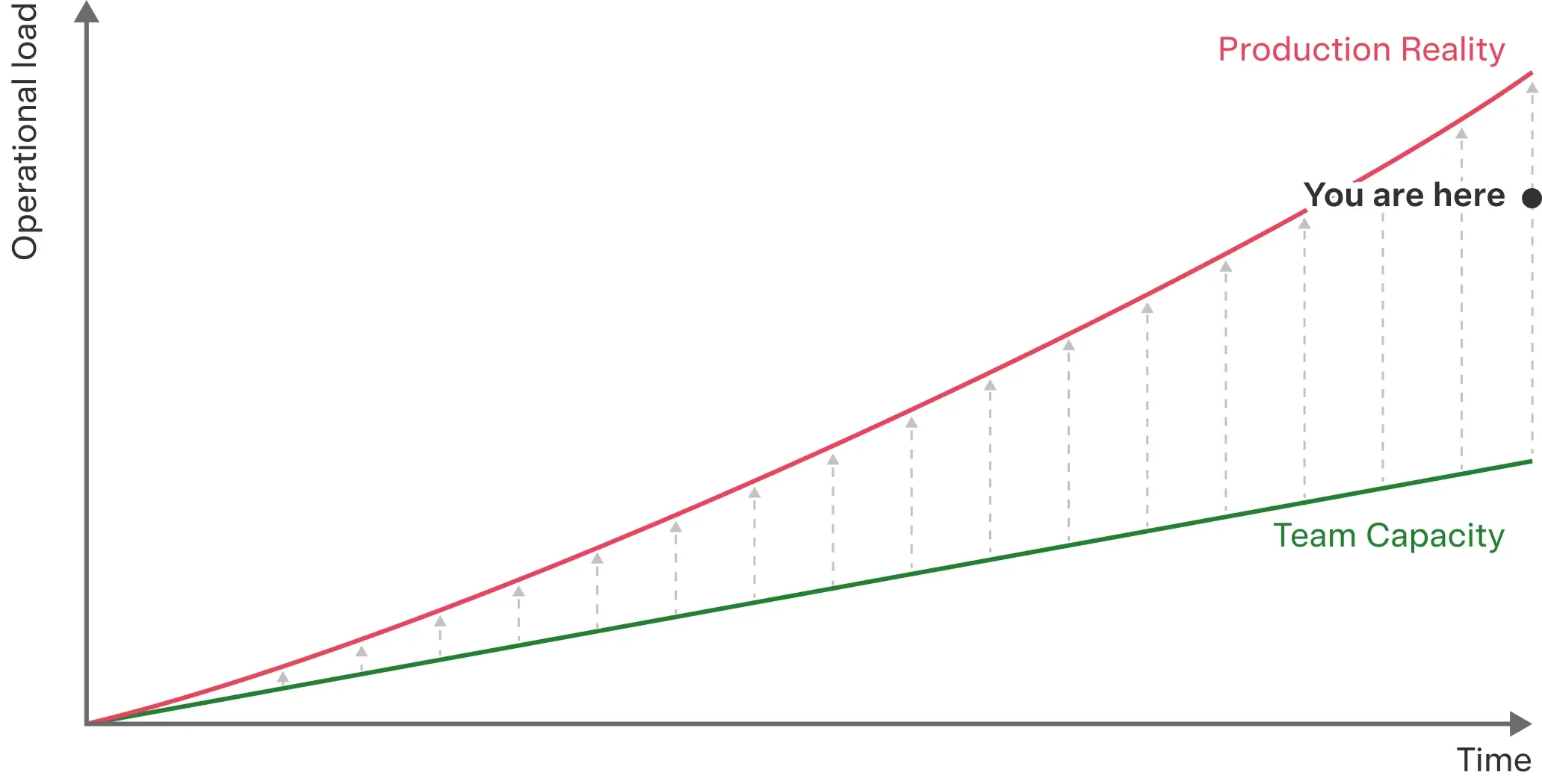
In 2025, while developers reported saving more than 10 hours per week using AI coding tools, 50% also reported wasting more than 10 hours per week, and 90% reported wasting at least 6 hours.9 The top sources of friction were finding information, switching context between tools, learning new systems, and coordinating across teams. These are exactly the kinds of problems teams see more of as production complexity grows.
Spotlight: How production work actually happens
Most discussions about production operations focus on incidents, but that’s only part of the picture. A significant share of the operational work that consumes engineering time happens outside of incident response, in the day-to-day work of understanding and maintaining production systems.
Two examples illustrate the range.
Example 1: The 45-minute fire drill
At 12:04 PM, a latency alert fires for a checkout service. The application engineer on call checks Datadog and sees the 95th percentile climbing. Error rates are flat, and CPU looks normal.
A deploy went out 18 minutes earlier, making it the obvious suspect. But the logs show no new stack traces. Instead, there are sporadic timeout errors from a downstream service.
A platform engineer is brought in to review Terraform history, but finds no recent infrastructure changes. An SRE, also pinged, searches Slack for prior incidents involving this dependency, recalling that six months ago a similar symptom turned out to be a connection pool misconfiguration.
Now three engineers are looking at multiple dashboards, log queries, and Slack threads. Eventually, they get on a video call to align context. 45 minutes later, they identify the issue: a recent configuration change reduced the maximum database connections. The pool exhausted under load, causing retries that amplified latency.
The team resolves the root cause, but the pattern is likely to repeat. Unless someone writes a detailed postmortem, and ensures it is discoverable and referenced in the future, the next time a similar alert fires, the investigation will likely start from scratch.
Example 2: The gradual regression
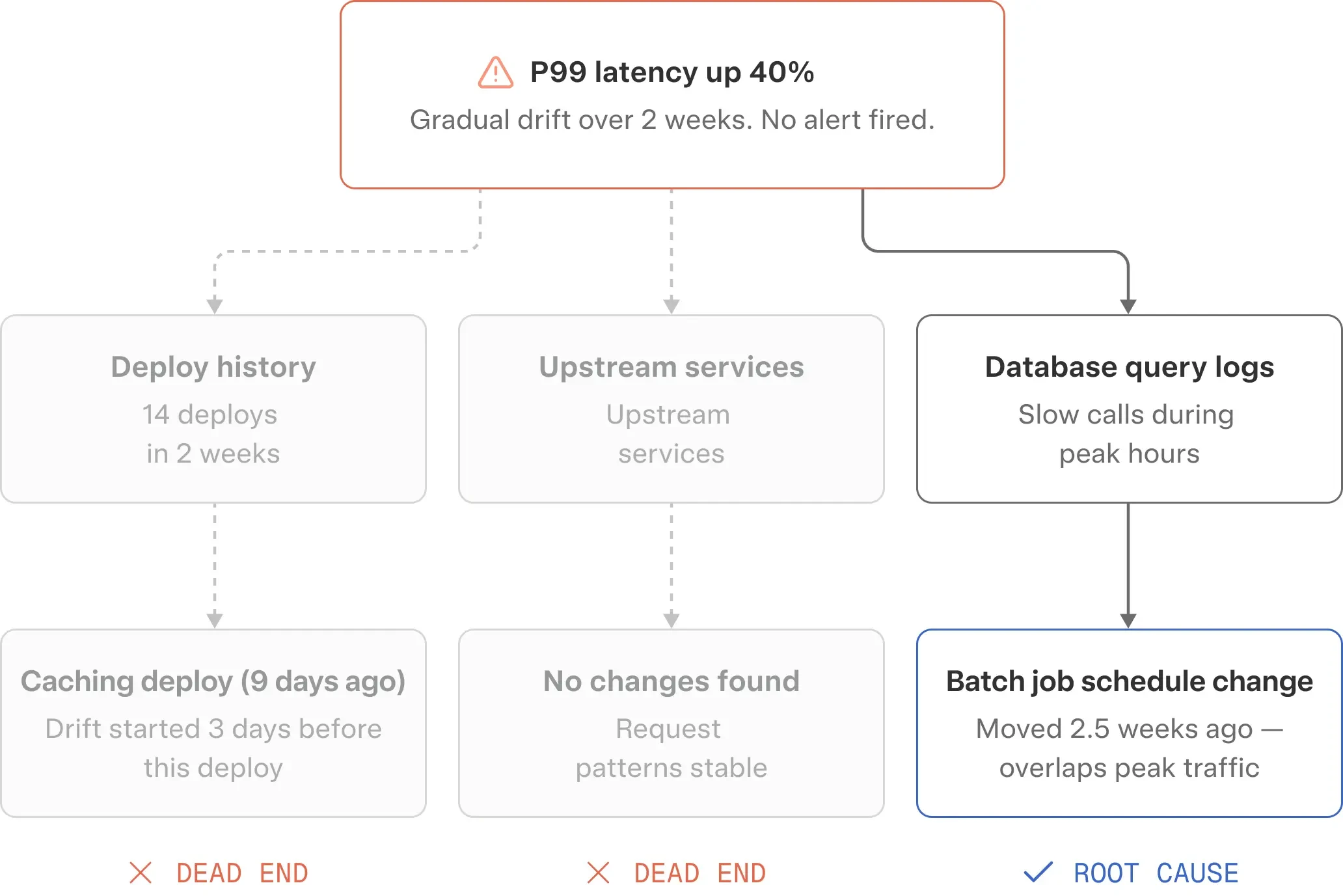
On Wednesday morning, a senior engineer notices during a routine review that p99 latency on the recommendation service has drifted up 40% over the past two weeks. No alert fired, because the degradation was gradual enough to stay under the threshold.
She spends the next hour trying to figure out what changed. She checks the deploy history, and finds there were 14 deploys to this service in the past two weeks. She scans the metrics for each one, looking for a step change. She finds a candidate: a deploy nine days ago that added a new caching layer. But the latency drift started three days before that deploy, not after it.
She pivots. She checks whether any upstream services changed their request patterns. She queries logs for slow database calls. She finds that a batch job, owned by a different team, was moved to a new schedule two and a half weeks ago, and it now overlaps with peak traffic hours, competing for database connections.
This was never an incident. No one was paged. But it took an experienced engineer over an hour to trace the cause, and the only reason it was caught at all is that she happened to look at that dashboard that morning.
The insight she built, including which services share database resources, how schedule changes ripple across teams, and what “normal” latency looks like for this service at different times of day, lives in her head. When she moves to a different team next quarter, it goes with her.
The path through Example 2 — The knowledge she built lives in her head
Which services share DB resources. How schedule changes ripple across teams. What “normal” latency looks like at different times of day. When she moves to a different team next quarter, it goes with her.
The pattern
Both examples follow the same shape: an engineer gathers signals from multiple tools, reconstructs context that isn’t written down anywhere, forms and tests hypotheses, and eventually arrives at an explanation. The first took 45 minutes across three engineers during an active incident. The second took over an hour from one engineer during routine work — and only happened because someone was paying attention.
In both cases, the investigation required cross-system reasoning, institutional knowledge, and judgment that no single tool provided. And it produced artifacts in the form of Slack threads and human memories that, unless recorded and indexed in some way, won’t be useful the next time a similar issue occurs.
This is the production work that AI SRE is designed to address: not just the fires, but the full spectrum of investigative and diagnostic work that keeps engineers from building.
AI SRE: Extending agents to production systems
The investigative work described above, such as correlating signals across tools, reconstructing context that isn’t documented, and forming and testing hypotheses under pressure, is exactly the kind of reasoning that modern AI agents are increasingly good at.
Agents can plan multi-step workflows, invoke production APIs, maintain context across a long investigation, and reason across structured and unstructured data. Production environments are API-addressable and data-rich, a natural operating environment for these capabilities.
This is what has given rise to a category of solutions known as AI SRE. Broadly defined, an AI SRE is an agentic system that automates production operations work: the cross-system investigation, diagnosis, and resolution that currently requires engineers to context-switch across dozens of tools and reconstruct understanding from scratch every time.
Most AI SREs focus on a core production workflow: the detect → diagnose → remediate loop.
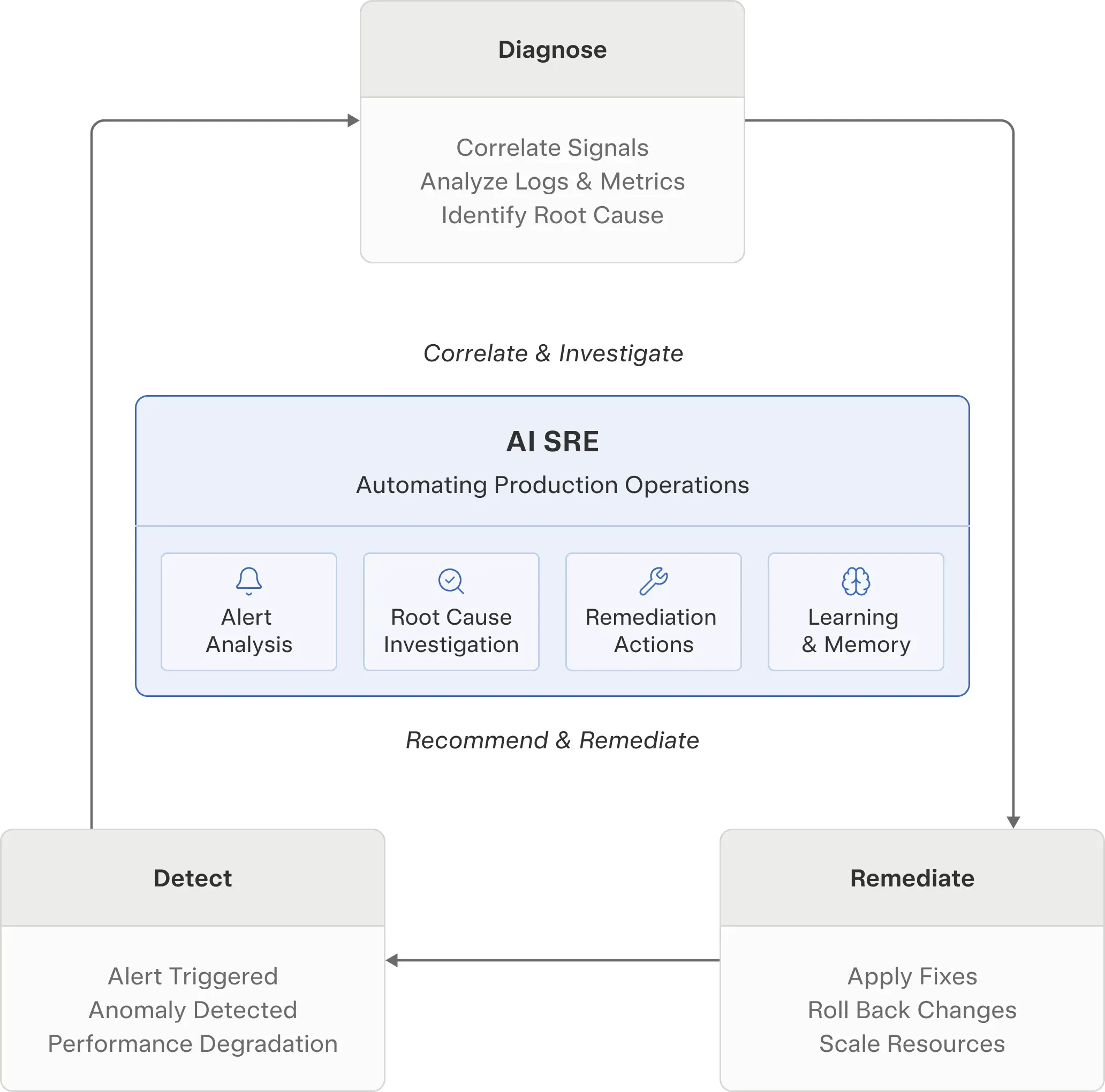
When an alert fires or a regression appears, engineers follow a familiar pattern. They:
- Interpret the signal and assess severity
- Correlate metrics, logs, traces, and recent deployments
- Form and test hypotheses about root cause
- Identify the responsible service or dependency
- Recommend or execute a remediation step
AI SRE systems are designed to participate in, and increasingly automate, this complex reasoning work. Depending on architecture and scope, an AI SRE may:
- Triage and cluster alerts into a coherent incident narrative
- Correlate telemetry across observability platforms
- Query infrastructure, CI/CD systems, and code repositories
- Identify likely root causes with supporting evidence
- Recommend remediation steps grounded in system state
- Execute pre-approved actions within defined guardrails
- Capture institutional memory from incidents and investigations
Importantly, AI SRE capabilities can extend beyond incident response. Agents that help with day-to-day debugging, alerting, knowledge retention, and even capacity planning and cost optimization all fall under the bucket of AI SRE.
Given the breadth of ways agents can be used in production workflows, teams evaluating AI SRE teams face a wide range of architectural choices, integration models, and autonomy levels.
The next section outlines the primary paths teams are taking, and the trade-offs inherent in each.
Part 2: The Forks in the Road
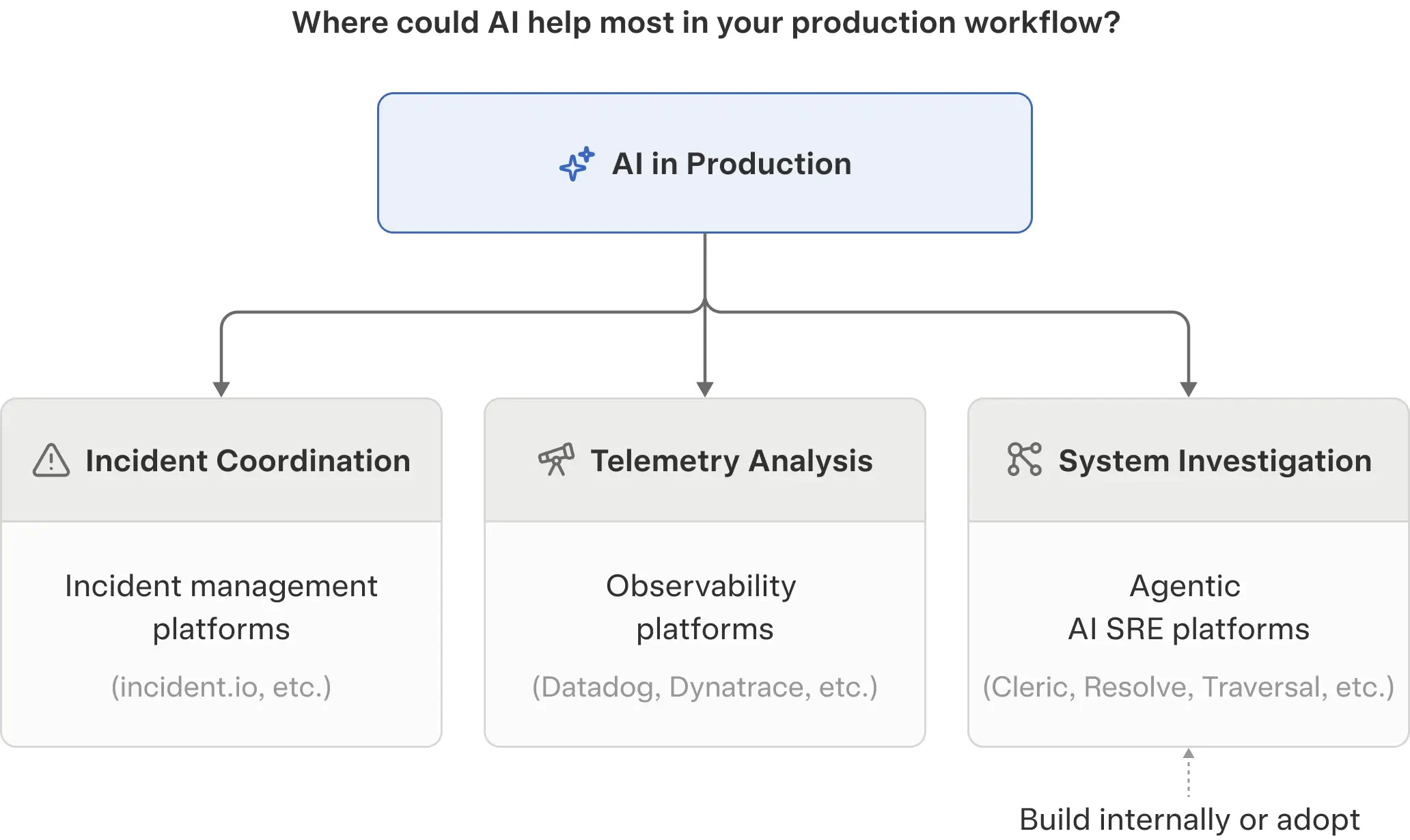
AI SRE solutions fall into 3 categories:
- Some tools focus on incident management, helping teams manage high-severity events.
- Others apply AI within observability platforms to analyze telemetry and help engineers interpret system behavior.
- A newer category of agentic AI SRE platforms focuses on investigating production systems by reasoning across many sources of operational context.
The diagram below provides a simple way to think about where these approaches fit.
Some teams also consider building their own AI SRE internally, a decision discussed in this section.
Incident management platforms
At a glance
- Strength: Reduces coordination overhead during incidents
- Weakness: Investigation capabilities are typically secondary to the incident lifecycle
- Best fit: Teams focused on improving incident response coordination and documentation
Incident management platforms are built primarily around the process of responding to incidents. Their core responsibility is coordinating people and communication during outages: declaring incidents, routing responders, managing incident rooms, tracking status, and documenting what happened.
AI capabilities in these systems are typically layered on top of the incident coordination workflow. The models operate on the context the platform already manages: alerts, incident channels, responder activity, timelines, and communication between teams.
Many incident platforms have also begun adding AI-assisted investigation features. For example, incident.io has introduced an AI SRE that can check recent deploys or code changes and suggest possible root causes to help responders understand what happened.
Example: What this looks like in practice
An alert fires for elevated API latency.
An incident management platform might automatically:
- declare a SEV2 incident
- create an incident channel
- page the responsible service owner
- summarize the alert context in the incident room
- begin an automated investigation
During that investigation, the platform’s AI SRE may:
- analyze telemetry associated with the alert
- check recent deploys or code changes
- compare the symptoms with similar past incidents
Based on this evidence, the system might propose a hypothesis such as:
The latency spike is likely related to the deploy of service checkout-api 15 minutes ago.
Similar error patterns occurred in incident #1423, which was caused by a misconfigured timeout on a downstream dependency.
The agent can then post this hypothesis into the incident channel along with supporting signals and suggested next steps. Throughout the incident, the platform may also summarize the investigation for responders, track key events in a timeline, and draft status updates for stakeholders.
Where it works best
If the biggest operational pain in your organization is running incidents, incident management platforms are often a great solution.
These tools are designed to make incident response structured and predictable. They help teams declare incidents quickly, pull the right people into the response, keep everyone aligned on what’s happening, and capture a clear record of how the issue was resolved. For organizations that experience frequent incidents or large multi-team outages, this coordination layer can remove a significant amount of operational friction.
They are especially valuable if your current incident response looks like:
- alerts triggering chaotic Slack threads
- unclear ownership of services
- responders joining incidents without context
- timelines and postmortems being reconstructed after the fact
In those environments, a dedicated incident management platform can dramatically improve response speed and clarity.
However, if the biggest operational cost in your environment is engineers spending hours investigating alerts and diagnosing production issues, you may find yourself pushing these tools beyond what they were originally designed for. Their AI SRE capabilities sit within a platform whose primary design is still centered on managing the incident lifecycle.
As a result, the agent’s main role is helping responders understand and resolve a specific incident. Investigation is typically organized around those events, rather than operating as a standalone system designed to continuously reason about the production environment.
Observability platforms
At a glance
- Strength: Powerful analysis of logs, metrics, and traces already collected by the observability platform
- Weakness: Investigation is limited to the telemetry the platform ingests
- Best fit: Teams whose operational overhead already centers around a single observability system
Observability platforms work by collecting and storing telemetry from production systems, typically metrics, logs, traces, and events. Engineers then query this dataset to understand how services behave and investigate issues when alerts fire.
Platforms like Datadog, Dynatrace, New Relic, Elastic, and Grafana are now beginning to add agentic capabilities. Some use the term AI SRE (like Datadog’s Bits AI SRE), while others describe the functionality as an AI assistant.
The platform ingests telemetry data, structures it, and stores it; the agent queries and analyzes it. In practice, this means the agent can examine telemetry patterns to:
- detect anomalies
- correlate signals across services
- summarize incidents or alerts
- identify possible root causes
- surface relevant dashboards or queries
This type of AI SRE operates exclusively on the platform’s telemetry dataset, rather than operating the broader production toolchain the way an engineer might during a full investigation. That’s a meaningful constraint, since a lot of investigative context lives outside telemetry entirely. And in larger organizations, telemetry itself is often spread across multiple platforms (Datadog, Splunk, CloudWatch, Grafana), so any single platform’s agent only sees part of the picture.
Example: What this looks like in practice
An alert fires for elevated API latency.
Inside the observability platform, the agent might:
- detect a spike in p95 latency for the affected service
- identify related error rates increasing across downstream services
- analyze traces to find the slowest spans in the request path
- surface logs associated with the failing dependency
Based on this analysis, the system might suggest a hypothesis such as:
Latency is likely related to increased response times from the payment-service dependency. Trace data shows requests spending 65% of total latency in that service beginning 12 minutes ago.
The agent can then highlight relevant dashboards, traces, and logs to help engineers quickly confirm or refute the hypothesis.
Where it works best
If the biggest operational cost in your organization is analyzing telemetry when alerts fire, an observability platform’s AI SRE might be just what you’re looking for.
These systems are designed to make it faster for engineers to explore logs, metrics, and traces, correlate signals across services, and understand what changed in the system. For teams that already rely heavily on an observability platform during debugging, AI features can significantly reduce the time it takes to navigate telemetry and surface relevant signals.
This approach works best when most of your production context lives inside a single observability platform. In those environments, the AI has a comprehensive dataset to analyze and correlate, which makes its hypotheses much more reliable.
However, many teams operate a fragmented set of observability platforms and infrastructure tools. The AI SRE inside any single platform can only see the signals that platform has ingested. If important context lives elsewhere, the agent will generate hypotheses based on an incomplete picture of the ground truth.
For teams whose operational time is dominated by investigations across multiple tools and signals, an observability platform’s AI can still speed up parts of the analysis, but it may not significantly reduce the cognitive overhead of working with production systems, and could in the worst case be actively misleading.
Agentic AI SRE platforms
At a glance
- Strength: Investigates production issues across multiple systems and signals
- Weakness: Requires deeper integration into the production environment
- Best fit: Teams spending significant engineering time investigating production issues
Agentic AI SRE platforms (e.g., Cleric, Resolve, and Traversal) take a different approach from incident management or observability tools. Instead of operating primarily within a single system, they investigate production environments by interacting with multiple operational tools across the stack.
These systems connect to the same tools engineers typically use during debugging: observability platforms, deployment systems, infrastructure tooling, source control, and incident records.
Rather than analyzing a single centralized dataset, the AI forms hypotheses and then gathers evidence by querying and operating these tools directly, much like an engineer would during an investigation.
For example, the agent might:
- query observability platforms for metrics, logs, and traces
- check recent deploys or configuration changes
- inspect infrastructure state or service dependencies
- review recent code changes
- compare the symptoms with similar past incidents
By combining signals from multiple systems, the agent can construct explanations about what is happening in production and suggest likely root causes.
Many agentic AI SRE systems also maintain a persistent operational memory. As the agent investigates incidents, analyzes alerts, and observes system behavior, it can store the reasoning paths, explanations, and resolutions it discovers. Over time this creates a growing knowledge base about how the production system behaves, what kinds of failures occur, and how similar issues have been resolved in the past.
This accumulated context allows the agent to recognize patterns, reference prior incidents, and reason about new problems using knowledge that would otherwise exist only in engineers’ heads or scattered across past incident records.
Example: What this looks like in practice
An alert fires for elevated latency in a checkout service.
An agentic AI SRE might begin an investigation by:
- querying metrics and traces to identify the affected services
- checking recent deploy history for changes around the time the issue began
- examining configuration or infrastructure changes
- reviewing past incidents with similar symptoms
Based on these signals, the system might propose a hypothesis such as:
Latency is likely caused by a schema migration deployed to checkout-api 12 minutes ago that added an unindexed query to the order lookup path. Similar symptoms occurred in incident #318, which was resolved by adding the missing index.
The agent can present the reasoning chain behind this hypothesis and suggest next steps for responders. In some implementations, the system may also be able to execute approved operational actions, such as gathering additional diagnostics or triggering safe remediation workflows.
Where it works best
If the biggest operational cost in your organization is engineers spending significant time investigating alerts and reasoning about behavior in production, agentic AI SRE platforms are designed to address exactly that problem.
In many modern systems, diagnosing issues requires engineers to correlate signals across multiple tools: observability platforms, deployment systems, infrastructure state, source control, incident history, etc. A large portion of operational time is spent moving between these systems, forming hypotheses, testing them, and gradually building an explanation of what is happening.
Agentic AI SRE platforms aim to automate much of this work by operating the same tools engineers use during debugging and synthesizing signals across the environment.
Just as importantly, these systems can retain and build on prior investigations. Over time they accumulate knowledge about how the system behaves, what kinds of failures occur, and how similar incidents have been resolved in the past. This persistent memory allows the system to reason about production issues using context that would otherwise live only in engineers’ heads or scattered across past incident records.
Because these platforms effectively replace investigative labor, they tend to be most valuable for teams where operational reasoning already consumes a meaningful amount of engineering time. If engineers are frequently interrupted to diagnose alerts, trace regressions, or piece together system behavior, an agentic AI SRE can significantly reduce that workload.
For teams that experience relatively few operational issues, or where investigation work is already minimal, the impact may be more limited.
Building your own AI SRE
At a glance
- Strength: Maximum flexibility and control over how the system investigates production issues
- Weakness: The investigation agent is only one component of a working system — measurement, learning, and environment understanding require deep, ongoing investment
- Best fit: Teams with simple environments where a basic investigation agent provides enough value on its own
Some organizations look at agentic tools like Claude Code or Cursor and think: we could wire this to our observability stack and build our own AI SRE. The components seem accessible — agent frameworks handle orchestration, most production systems expose APIs, and a proof of concept can come together in a few days.
This instinct is reasonable. And for some teams, it’s the right call. But it’s worth understanding what a complete system actually requires, and making a conscious decision about what you will and won’t sign up for.
Getting basic investigation working is the easy part
The first version of a DIY AI SRE usually looks like an agent connected to a few operational tools: your observability platform, deployment system, maybe source control. When something goes wrong, the agent queries those systems, gathers signals, and proposes a hypothesis.
This can work surprisingly well for straightforward problems. If an alert fires right after a deploy, and the logs show a new stack trace, most agents will connect the dots. The challenge is everything that comes after.
An investigation agent alone is an open-loop system
In every AI domain where automation actually works, there’s a feedback mechanism that tells you whether the AI got it right. Code generation has tests, self-driving has miles per disengagement. But there’s no equivalent for production operations.
When your DIY agent says “the root cause is a retry storm from a downstream service,” there’s no test to run, and no ground truth, unless you built it.
Without that feedback, you have an open-loop system. It might produce useful summaries and plausible hypotheses. But you can’t improve it systematically, you can’t build confidence in its outputs, and you can’t let it take action. After 100 investigations, you still can’t answer a basic question: is this thing actually getting better?
This is the wall that every team building agents for production operations eventually hits. Breaking through it requires investment in the system underneath the investigation agent, and verification is the hard part. Without a way to measure whether a diagnosis was correct, the agent is open-loop: it produces output but has no signal to improve from. Without verification, you can’t improve. With it, every investigation feeds a measurable accuracy estimate and a memory the next investigation can draw on.
An open-loop system can still scale, but only by adding humans alongside it: deployment engineers who carry environmental knowledge in their heads and tune the system per customer. The closed-loop alternative is to make the system itself the thing that learns the environment.
What a closed-loop system actually requires
Working backward from a system that can reliably investigate and eventually act on production issues, you need several capabilities beyond the agent itself:
Measurement and verification
How do you know the agent’s diagnosis was correct? Ground truth in production is rare and slow, since engineers won’t always rate the agent’s work, and when they do, it might be days later. A real measurement system has to triangulate across many signals: did the alert recur after the suggested fix? Did downstream services stabilize? Did the engineer take a completely different action than what the agent recommended? Each signal is noisy individually. Combining them into a reliable accuracy measure that understands each signal’s failure modes, weights them appropriately, and calibrates across different types of problems, is a serious engineering challenge.
Confidence scoring
Once you can measure accuracy, you can break it down by problem type. Maybe your agent is right about deployment-related issues 90% of the time but only 50% on network partitions. That distinction is what allows the system to handle the first category with less oversight and escalate the second. Without it, every recommendation requires the same level of human judgment regardless of track record. Building this requires aggregating verified outcomes across many investigations and problem types. It’s a bootstrapping challenge where you need outcome data to calibrate, but you need calibration to know which outcomes to trust.
Operational memory and learning
A stateless agent starts from zero on every investigation, working only with whatever knowledge is built into the model. It works for simple problems. It falls apart for anything that requires context about your specific environment. When an engineer corrects a diagnosis, when a specific investigation approach works well for your stack, when your team’s operational preferences emerge through interactions (“we always roll back deploys before debugging”) — a working system captures all of this. The system should compound in value with every investigation. A DIY agent built with a coding tool doesn’t do this. It starts from scratch every time, or at best maintains a static prompt that someone manually updates.
Environment understanding
Production environments never sit still. Multiple teams make changes simultaneously, often without coordinating. The topology, config, baselines, and organizational context are all moving targets. Your payments service runs hot on Fridays. Your recommendation engine’s latency doubles during A/B tests and that’s expected. A working system needs to know how the organization actually operates, not just what services exist and how they connect. Building this picture requires continuous observation, and it changes constantly.
Cross-environment learning
The same type of problem (e.g., connection pool exhaustion) looks completely different at a company running PostgreSQL on Kubernetes versus one using Aurora with PgBouncer. The symptoms, metrics, logs, and fixes are all different. But the structural pattern (increasing latency + growing active connections + stable query volume = connection pool saturation) transfers. Extracting these reusable patterns from implementation-specific details is a scale problem that a single team building internally will never solve.
These modules are deeply connected
These aren’t independent features you can add one at a time. They form a flywheel:
- Learning makes the system better at investigating
- Measurement proves it’s getting better
- Confidence scoring identifies where the system is reliable enough to act with less oversight
- Every investigation generates more data for learning and measurement
Without measurement, your learning system has no signal to learn from. You’re just accumulating memories with no way to know which ones are accurate. Without learning, measurement is just a report card with nothing to improve. Without both, you can never move from investigation to autonomous action.
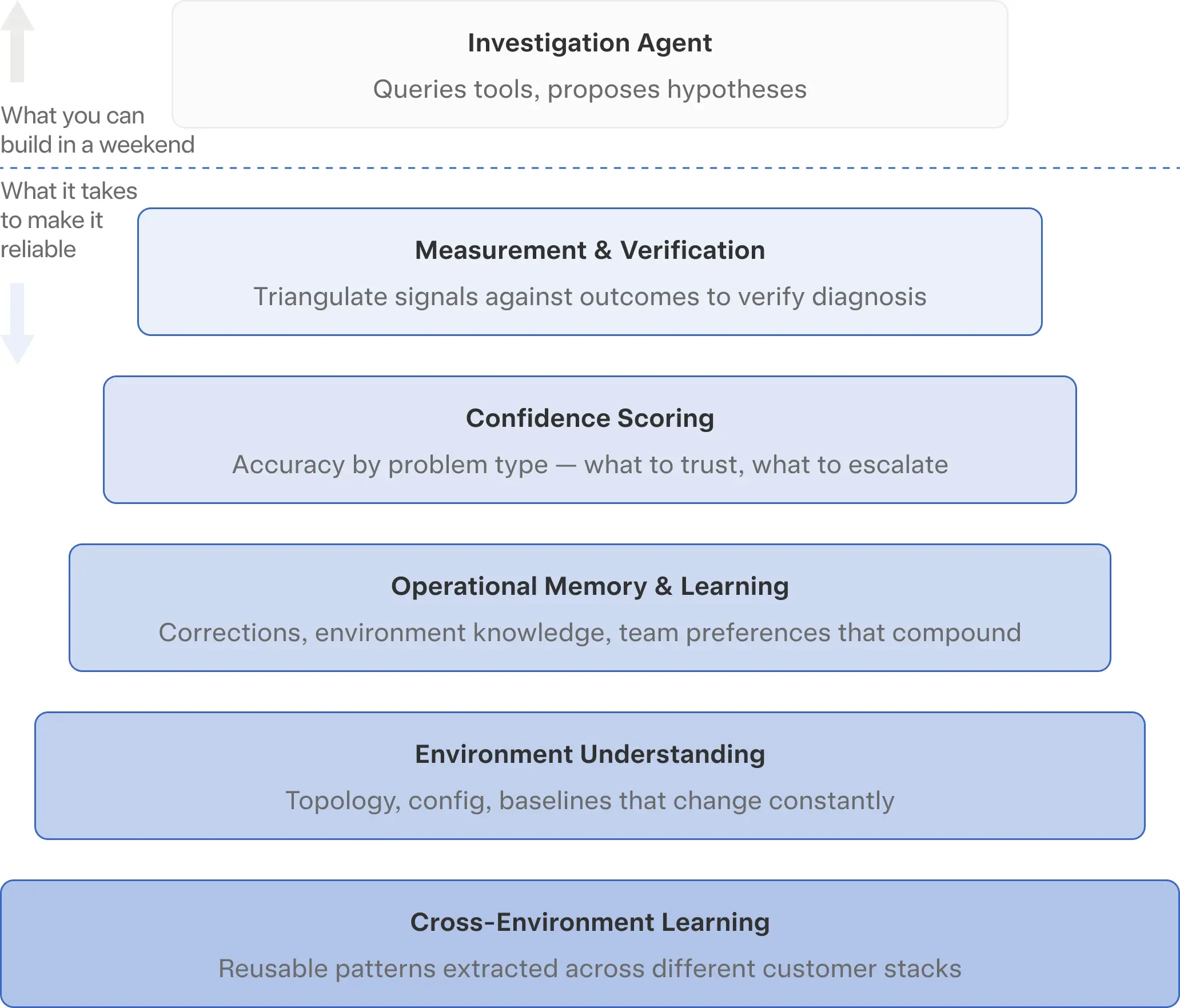
The real question: what are you signing up for?
Building a basic investigation agent is a weekend project. Building the measurement, learning, and verification systems that make it reliable is a multi-year platform investment.
Most teams that start down the DIY path discover this gradually. The agent works well enough for the first few months, but then it plateaus. It keeps making the same kinds of mistakes. It doesn’t learn from corrections. It can’t tell you which types of problems it handles well. Engineers stop trusting it because there’s no data to support its recommendations, and it eventually becomes shelfware.
Some questions to ask before building:
- After 100 investigations, will you be able to tell which problem types the system handles well and which it doesn’t?
- Does it learn from corrections, or does it start from scratch every time?
- Can you show your VP of Engineering that it’s actually reducing engineering time?
- Who will build and maintain the evaluation infrastructure to know if it’s improving or regressing?
- Are you prepared to maintain this as an internal platform long-term?
If the answer to most of these is “no, but the basic investigation is enough for now,” that’s a legitimate choice, especially for smaller or simpler environments. But if you need a system that compounds in value over time, you’re looking at building significantly more than an agent.
Part 3: Comparing Agentic AI SRE Platforms
You may not need to read the rest of this guide. If you’ve decided to build an AI SRE yourself using tools like Claude Code, that’s a perfectly reasonable path for some teams. And if you plan to rely on agentic features built into your observability or incident management platforms, that may be enough depending on your environment.
But if you’ve concluded that you want a dedicated agentic AI SRE platform, something purpose-built to investigate production systems across your stack, the next question is which approach to choose.
Most readers will already have an incumbent vendor whose core product ships with a companion AI SRE feature (Datadog, New Relic, AWS, Azure, PagerDuty, incident.io). This guide is for buyers who’ve evaluated those offerings and concluded they need a purpose-built AI SRE platform, not a feature inside the tool they already own.
In practice, most teams evaluating this category end up looking at three platforms: Cleric, Resolve, and Traversal. All three are trying to solve the same core problem: helping engineers understand what’s happening in production systems. But they come at it from very different directions.
The differences fall along two axes: how each platform investigates problems, and how it gets deployed and learns a customer’s environment.
How the platforms differ
Which platform fits your team?
ChooseCleric if…
…your engineers spend significant time investigating production issues (e.g., debugging regressions, tracing unexpected behavior, correlating signals across tools) and you want a system that gets better at this over time. Cleric is built around the everyday investigative work that consumes engineering hours, not just major incidents. It’s particularly well suited for teams operating complex systems where context is spread across many tools and the knowledge of how things work lives in engineers’ heads.
ChooseResolve if…
…your biggest operational cost is engineers repeatedly executing the same remediation steps for well-understood problems. If your team maintains runbooks and operational playbooks, and the bottleneck is the manual effort of following them, Resolve can automate those workflows. It’s strongest in large infrastructure environments with frequent operational alerts where the right response is known but still requires human intervention to execute.
ChooseTraversal if…
…your hardest incidents involve complex cascading failures across many services, and the main challenge is figuring out which event caused which downstream effect. Traversal’s causal modeling approach is designed to narrow thousands of correlated telemetry signals down to the most probable chain of events. It’s most valuable for large, highly interconnected distributed systems with mature observability practices already in place.
Traversal
Traversal launched in 2025 with a founding team that brings deep research backgrounds in causal machine learning, including professors from Columbia and Cornell. The company’s central thesis is that complex cascading failures across many services, which can be the hardest production incidents to resolve, are fundamentally causal inference problems.
When something breaks in a large microservice architecture, you’re not looking for a single bug. You’re trying to figure out which event caused which other event across a web of services, infrastructure, and configuration changes. Traversal’s bet is that formal causal modeling can solve this better than an engineer manually tracing signal propagation through a dependency graph.
Approach
Modern observability platforms collect massive amounts of telemetry, e.g., metrics, traces, logs, infrastructure state, and deployment events. When an incident occurs, engineers typically look for signals that correlate with the failure: a metric spike, a recent deployment, a service that began failing at the same time.
The problem is that in large systems, these correlations produce hundreds of possible explanations. Many signals change during an incident, and most of them are downstream effects rather than the root cause.
Traversal attempts to cut through this noise by modeling the causal structure of the system itself. The platform constructs a representation of the system’s dependency graph and analyzes how signals propagate through that structure. Using techniques from causal machine learning, the system evaluates how changes in one part of the system influence behavior elsewhere.
When an incident occurs, rather than listing correlated signals, Traversal attempts to infer the most likely causal chain behind the failure: the triggering event, the intermediate dependencies involved, and the propagation path through the system. The result is an explanation backed by telemetry evidence at each step.
For engineers debugging a complex cascading failure, this can dramatically reduce the investigation space, narrowing thousands of signals down to a small set of events that plausibly explain the incident.
Where it tends to work best
Traversal’s approach is most compelling in a specific scenario: incidents where a failure cascades across many services, and the hardest part of the investigation is figuring out which upstream event triggered the cascade. Think of a situation where an outage takes down checkout, but the actual root cause is a configuration change three hops upstream in a service the on-call engineer has never touched.
In situations where the dependency graph is deep, the propagation path is non-obvious, and engineers would otherwise spend hours reconstructing the chain of events, Traversal’s causal modeling can dramatically narrow the search space.
However, these kinds of complex cascading failures represent a relatively small fraction of the operational work most teams deal with day to day. The majority of engineering time spent on production issues goes to more routine work: investigating alerts, debugging regressions, tracing unexpected behavior after a deploy, figuring out why a metric changed. Traversal isn’t designed to address that broader category of operational work.
As a result, Traversal tends to be most valuable for organizations that meet a specific set of conditions simultaneously: they operate large, highly interconnected distributed systems; they experience frequent multi-service cascading failures (not just routine alerts); they already have mature, comprehensive observability coverage; and the biggest bottleneck in their incident response is reconstructing causal chains across services, not the investigation itself.
Considerations
Traversal’s approach depends heavily on the quality and completeness of the underlying telemetry data. Because the system models relationships between components, environments with inconsistent instrumentation or limited observability coverage provide less signal for causal modeling.
The platform is designed for analyzing incidents, not for managing operational workflows, automating remediation, or handling the everyday investigative work that makes up the bulk of most teams’ production burden. Teams whose operational costs are spread across routine debugging, alert investigation, and knowledge management may find that Traversal addresses only one slice of the problem.
It’s also worth noting that Traversal’s causal modeling approach is most differentiated in the largest and most interconnected systems. In smaller or more modular environments, engineers can often trace failures across a handful of services without formal causal inference, and the overhead of maintaining a causal model may not justify the benefit.
For teams that do operate at the scale and complexity where cascading failures are a regular occurrence, Traversal offers a genuinely differentiated approach to a problem that other tools don’t address as directly.
Resolve
Resolve approaches AI SRE from a different direction: the automation of operational workflows. Where other platforms focus on helping engineers understand what’s happening in production, Resolve is designed to skip past the explanation and execute remediation steps directly.
The company’s background reflects this perspective. Resolve grew out of the broader world of IT operations automation. The core insight behind the platform is that many incidents follow familiar patterns, and engineers often end up executing the same remediation steps over and over again.
Resolve’s thesis is that these kinds of operational responses can be handled automatically, allowing engineers to focus on deeper work.
Approach
Resolve acts as an automation layer across the operational stack. The platform integrates with infrastructure systems, observability tools, cloud APIs, and deployment pipelines, giving it visibility into both the state of the system and the mechanisms required to modify it.
When an incident occurs, the system analyzes telemetry and operational context to determine what investigation steps and remediation workflows should run in response. These workflows often resemble the runbooks engineers would execute manually during an incident.
For example, an infrastructure issue might trigger a sequence like:
- collect diagnostic data from affected services
- check the health of underlying infrastructure
- identify resource constraints or failed dependencies
- execute a remediation step such as restarting a service or reallocating resources
Rather than surfacing these steps for an engineer to execute, Resolve is designed to run them automatically, using AI to determine which actions are appropriate in the context of the incident.
Over time, organizations can expand these workflows to cover a wide range of operational scenarios. As a result, many incidents that would normally require on-call intervention can be resolved without human involvement.
Where it tends to work best
Resolve’s approach is most effective in environments where the response to most incidents is already well understood. The problem isn’t figuring out what’s wrong, it’s that someone still has to manually execute the fix.
This is common in large infrastructure environments where many alerts correspond to known operational problems: resource exhaustion, unhealthy nodes, failed deployments, or services that need to be restarted. Engineers follow the same diagnostic and remediation steps each time, and the bottleneck is the manual effort of executing them, not the investigation itself.
Resolve is well suited for teams where:
- most incidents map to known runbooks or operational playbooks that are already well defined
- the primary pain is on-call engineers executing repetitive remediation, not diagnosing unfamiliar problems
- the organization is comfortable delegating control to an automated platform that acts directly in production
For these teams, the value is clear: incidents that used to require a human in the loop can be handled automatically.
Considerations
The tradeoff with an automation-first approach is that it works best when the problem space is well understood. Resolve’s strength is executing known responses to known problems. When an incident involves unfamiliar behavior, subtle interactions between services, or a root cause that doesn’t match an existing pattern, the system has less to offer, because the right response hasn’t been defined yet.
This creates a natural boundary. Automation platforms handle the routine well, but the investigative work of figuring out what’s actually wrong in novel situations is a different problem. Teams that experience a mix of routine operational issues and genuinely unfamiliar production behavior may find that Resolve addresses one category but not the other.
The platform also typically requires meaningful initial setup to define the workflows that power its remediation capabilities. Organizations adopting the system invest time encoding operational knowledge into automation rules and runbooks. And because the system executes actions directly in production, teams need clear governance around what types of automated responses are permitted and under what conditions.
Finally, it’s worth noting that autonomous remediation requires a high degree of trust in the system’s judgment about when to act. Unlike a system that builds toward autonomy gradually, earning trust on specific problem types by demonstrating accuracy over time, Resolve’s model is designed around autonomous action from the start. For some organizations this is exactly what they want. For others, particularly those operating systems where an incorrect remediation could cause more harm than the original issue, a more graduated approach to autonomy may be preferable.
Cleric
Cleric takes a different approach to AI SRE, starting from the observation that most operational engineering time is spent on the everyday work of understanding production systems. Work like debugging regressions, investigating why a deploy changed system performance, tracing unexpected behavior across services, or figuring out whether an alert is a real problem or noise.
This work is investigative by nature, and it has two properties that make it particularly hard to automate well. First, it requires context that’s spread across many tools and teams (observability platforms, deployment systems, Slack threads, incident history, and the heads of the engineers who’ve seen the problem before). Second, the knowledge generated during these investigations almost never accumulates. The next time a similar issue occurs, the investigation starts from scratch.
Cleric’s thesis is that both the investigative work and the knowledge it produces can be systematically captured, measured, and automated, and that doing so is the path from an investigation tool to a system that can eventually act on production problems with demonstrated reliability.
Approach
Cleric operates as an investigative layer across the production stack. When something in production changes (e.g., a regression appears, a system behaves unexpectedly, or engineers want to understand the impact of a deployment) the system begins an investigation similar to what an experienced engineer would perform.
This investigation can involve:
- examining metrics and traces across relevant services
- querying logs across multiple systems
- identifying recent deployments or configuration changes
- tracing dependencies between services
- checking historical incidents or known failure patterns
Rather than performing a single analysis step, Cleric behaves like an engineer would: it iteratively gathers information, forms hypotheses about possible causes, and tests those hypotheses by collecting additional data. The platform connects to observability systems, infrastructure tooling, deployment pipelines, and operational context from sources like incident tickets, documentation, and Slack/Teams.
The hardest problem in building an agent for production operations is verification. Without a way to measure correctness, an investigation agent is open-loop. It produces answers but has no feedback signal to improve from, and a human has to verify every result.
Cleric’s approach, which it calls the Verification Engine, is to triangulate across sparse environmental signals after the fact, like whether the alert recurred, whether downstream services stabilized, whether metrics recovered, and whether the engineer overrode the recommendation. No single signal is conclusive, but combined, they produce a measure of correctness that doesn’t depend on a human grading every investigation. This produces accuracy scores broken down by problem type, updated with every verified outcome.
The second component is the Decision Model, which captures how problems actually get solved in a given environment. Every investigation produces decision traces: which signals get checked, how engineers distinguish root cause from symptom, when they escalate, which corrections they make. These traces normally disappear into Slack threads and individual memory. Cleric captures them and matches them against verified outcomes patterns. Over time the system gets more precise on the kinds of problems that actually occur in the team’s environment.
Together, these two components close the loop. Decision traces tell the system how problems get solved, while verification tells it which of those solutions actually worked. Every investigation adds to the model, and every verification tells the model what’s worth keeping.
As accuracy scores climb on specific problem types, the system earns the right to act on those problems with less human oversight. Rather than asking engineers to trust autonomous remediation upfront, the system builds that trust through evidence. On problem types where accuracy is proven, the system can handle detection, diagnosis, resolution, and verification end to end. On problem types where it’s still learning, it escalates to an engineer with a precise recommendation and supporting evidence.
Cleric also emphasizes transparency in its reasoning. Instead of producing opaque recommendations, the system surfaces the signals it examined, the dependencies involved, and the sequence of events that led to its conclusions. Engineers can inspect this reasoning and verify it against their own understanding of the system.
Where it tends to work best
Cleric is built for teams where day-to-day production investigation has become a meaningful tax on engineering time. Its core bet is that the value in production operations comes from what a system learns across investigations.
Take Example 2 from earlier in this guide: the gradual latency drift on the recommendation service that turned out to be caused by a rescheduled batch job from a different team. The first time Cleric saw a problem like this, it would work the way the engineer did, pulling deploy history, ruling out the caching layer, checking upstream services, querying database logs, and eventually identifying the batch job as the source of contention.
When a similar drift appears two weeks later on a different service, Cleric pulls the prior investigation, recognizes the batch job is back on the schedule that caused the original problem, and surfaces the diagnosis with the previous evidence attached. The on-call engineer doesn’t need to recognize the pattern, because the system already has.
Most production investigations look more like this than like a major incident. They’re slow, they’re scattered across tools, and the answer almost always depends on something an engineer learned during a previous investigation that lived only in their head. Cleric is built for teams whose operational time is dominated by this kind of work.
Considerations
Cleric’s graduated approach to autonomy means that fully autonomous remediation is not available from day one. Teams looking to automate known operational workflows immediately may find that automation-first platforms reach that capability faster for well-understood problems.
The platform delivers the most value in environments with sufficient observability coverage and access to operational context. By design, the system earns the right to act autonomously on specific problem types through demonstrated accuracy. Cleric’s accuracy scores are built from verified outcomes, and systems with limited telemetry give the Verification Engine less signal to work with.
Cleric’s approach also requires time to compound. The operational memory, environment understanding, and confidence scoring that make the system increasingly valuable are built through sustained use. Teams evaluating the platform on a short proof-of-concept may see capable investigation but not yet the full compounding effect that develops over months of operation.
Conclusion
AI SRE is a new category, and the landscape is moving fast. The right choice for your team depends on where your operational pain actually lives, and that answer is different for every organization.
If your biggest challenge is coordinating people during incidents, an incident management platform may be the right starting point. If most of your investigative work happens inside a single observability tool, the AI features built into that platform may be enough. If you have a strong platform team and a simple environment, building something internally is a legitimate option.
But if your engineers are spending significant time investigating production issues across fragmented tools, reconstructing context that should already exist, and rediscovering things the team has solved before, that’s the problem purpose-built agentic AI SRE platforms are designed to solve.
Among those platforms, the differences come down to what you’re optimizing for. Traversal applies causal modeling to the hardest cascading failures. Resolve automates known operational workflows for well-understood problems. Cleric measures its own accuracy against real outcomes and uses what it learns from every investigation to get more precise on the problems specific to your environment. Every other agent in this space is open-loop. Cleric is closed-loop.
We obviously believe in the approach we’re building at Cleric. But more than anything, we want teams to make this decision with clear information. If this guide helped you think through the options more concretely, it did its job, regardless of which direction you go.
- 1 https://www.atlassian.com/incident-management/2024-state-of-incident-management
- 2 https://survey.stackoverflow.co/2025/ai/
- 3 https://www.infoworld.com/article/3831759/developers-spend-most-of-their-time-not-coding-idc-report.html
- 4 https://www.vmware.com/docs/vcf-modern-workloads-solution-brief
- 5 https://www.okta.com/reports/businesses-at-work/
- 6 https://grafana.com/observability-survey/2024/
- 7 https://survey.stackoverflow.co/2025/ai/
- 8 https://dora.dev/research/2024/ai-preview/
- 9 https://www.atlassian.com/blog/developer/developer-experience-report-2025
